XML相关安全问题
XML基础
XML相关
XML的来源
XML有两个先驱——SGML(标准通用标记语言)和HTML(超文本标记语言),这两个语言都是非常成功的标记语言。SGML多用于科技文献和政府办公文件中,SGML非常复杂,其复杂程度对于网络上的日常使用简直不可思议。HTML免费、简单,已经获得了广泛的支持,方便大众的使用。而XML(可扩展标记语言)它既具有SGML的强大功能和可扩展性,同时又具有HTML的简单性。
但是XML与HTML有很多不同,其主要差异为:
XML 被设计为传输和存储数据,其焦点是数据的内容;
HTML 被设计用来显示数据,其焦点是数据的外观。
即HTML 旨在显示信息 ,而 XML 旨在传输信息。
什么是 XML?
XML 指可扩展标记语言(EXtensible Markup Language)。
XML 的设计宗旨是传输数据,而不是显示数据。
XML 是 W3C 的推荐标准。
XML 不会做任何事情。XML 被设计用来结构化、存储以及传输信息。
XML 语言没有预定义的标签。
什么是XSL?
XSL 指扩展样式表语言(EXtensible Stylesheet Language),XML本身就是一个XML文档,它是通过XML进行定义的,遵守XML的语法规则,是XML的一种具体应用。
如果说HTML的样式表是CSS,那么XML的样式表就是XSL。但XSL比CSS更强大。XSL - 不仅仅是样式表语言。
XSL 包括以下三部分,
XSLT:一种用于转换 XML 文档的语言。
XPath:一种用于在 XML 文档中导航的语言。
XSL-FO:一种用于格式化 XML 文档的语言。
XML基本语法
基本格式
示例代码:
1 | |
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> 称为 XML prolog ,用于声明XML文档的版本和编码,是可选的,必须放在文档开头,standalone值是yes的时候表示DTD仅用于验证文档结构,从而外部实体将被禁用,但它的默认值是no,而且有些parser会直接忽略这一项。
基本语法:
XML prolog 用于声明XML文档的版本和编码,是可选的,必须放在文档开头。
XML 文档必须有根元素。
XML 必须正确地嵌套:在一个XML元素中允许包含其他XML元素,但这些元素之间必须满足嵌套性。
XML 标签对大小写敏感:在标记中必须注意区分大小写,在XML中,
<TEST>和<test>是两个截然不同的标记。所有 XML 元素都须有关闭标签:结束标记除了要和开始编辑在拼写和大小上完全相同,还必须在前面加上一个斜杠“/”,若开始标记
<test>,结束标记则为</test>。XML严格要求标记配对,像HTML中的<br>、<hr>的元素形式在XML中是不合法的。当一对标记之间没有任何文本内容时,可以不写结束标记,在开始标记的末尾加上斜杠”/”来确认,例如:<test />这样的标记被称为“空标记”。XML 有效使用属性(属性值须加引号):标记中可以包含任意多个属性。在标记中,属性以名称/取值对出现,属性名不能重复,名称与取值之间用等号“=”分隔,且取值用引号引起来。举个例子:
<衣服 品牌=“耐克” 类型=“T恤” >若多个字符都需要转义,则可以将这些内容存放到CDATA里面,
<![CDATA[ 内容 ]]>
或许有人会问,上面的bookstore、book啥的我们都没定义,可以直接用吗?
其实,如果没有使用 DTD 或 XML Schema,XML 是 自由结构 的。也就是说,你可以直接使用 <bookstore> 和 <author> 等元素,而不需要显式定义它们。
在这种情况下,XML 仅需要符合基本的语法规则,比如标签正确嵌套、属性正确书写等。
但是,我们本节必须要引入DTD的概念,因为实际利用中我们还是需要对元素进行声明的。
DTD概念
XML 文档有自己的一个格式规范,这个格式规范是由一个叫做 DTD(document type definition) 的东西控制的。
DTD用来为XML文档定义语义约束。是XML文档中的几条语句,用来说明哪些元素/属性是合法的以及元素间应当怎样嵌套/结合,也用来将一些特殊字符和可复用代码段自定义为实体。
可以嵌入在XML文档中(内部声明),也可以独立的放在另外一个单独的文件中(外部引用)。
DTD的引入方式
DTD(文档类型定义)的作用是定义 XML 文档的合法构建模块。DTD 可以在 XML 文档内部声明,也可以文档外部引用。
当然,这里的内部声明与外部引用是以XML 文档为界限(从定义也可以看出),在xml文档内部声明的就是内部实体,引用xml外面的文档就是外部实体(文档外面可以是本地的其他文档,也可以是互联网中的XML 文档)。
内部 DTD
使用内部的dtd文件,即将约束规则定义在xml文档中
1 | |
示例代码:
1 | |
外部 DTD
(1)引入外部的dtd文件(本地的)
1 | |
(2)引入外部的dtd文件(网络上)
1 | |
示例代码:
1 | |
上面引用的test.dtd的内容如下,
1 | |
DTD的定义方式
实际上这个标题不够好,我们这里讲的是
DTD定义 XML 文档结构和内容的关键机制
在 DTD(文档类型定义)中,用于定义 XML 文档结构和内容的关键机制主要包括以下几种,
元素声明:
用于定义 XML 文档中的元素及其内容模型。
语法:<!ELEMENT element-name (content-model)>
属性声明:
用于定义元素可能具有的属性及其类型。
语法:<!ATTLIST element-name attribute-name attribute-type default-declaration>
实体声明:
用于定义可重用的文本或外部资源。
语法:内部实体为<!ENTITY entity-name "value">,外部实体为<!ENTITY entity-name SYSTEM "URI">
符号(Notation)声明:
用于定义非 XML 数据的格式。
语法:<!NOTATION name PUBLIC "public-identifier" SYSTEM "URI">
示例,<!NOTATION gif PUBLIC "image/gif">
注释:
在 DTD 中可以添加注释,便于说明文档结构。
格式:<!-- This is a comment -->
注意,
关键是要区分下面几种DTD 声明关键词,
ELEMENT:用来定义 XML 文档的结构,例如定义根元素包含哪些子元素。
ATTLIST:用来定义元素的属性,例如在
<book>元素中定义category属性。(注意区别元素的类别与元素的属性)ENTITY:用来定义固定的文本片段或引用外部文件,例如书籍作者名称或外部 XML 文件。
Notation:用于定义非 XML 数据的格式,如图片、视频等
DTD详解
我们这里详细解析一下DTD元素、属性以及实体,尤其是实体,是重中之重。
DTD元素
元素声明语法:
1 | |
其中元素名称是我们自己编的,这里讲一下内容模型。
内容模型(content-model)可以是以下之一,
EMPTY:表示元素是空元素ANY:表示元素可以包含任何内容#PCDATA:表示元素包含文本数据。(child1, child2, ...):表示元素包含其他子元素,且子元素的顺序必须匹配。*、+、?:表示重复规则,分别为 0 次或多次、1 次或多次、0 次或 1 次。|:表示选择规则,即多个子元素中的任意一个。
示例,
1 | |
注意,
PCDATA的意思是被解析的字符数据。PCDATA是会被解析器解析的文本。这些文本将被解析器检查实体以及标记。文本中的标签会被当作标记来处理,而实体会被展开。被解析的字符数据不应当包含任何&,<,或者>字符,需要用& < >实体来分别替换。
CDATA意思是字符数据,CDATA 是不会被解析器解析的文本,在这些文本中的标签不会被当作标记来对待,其中的实体也不会被展开。
我们这里对比下元素与实体的声明方法,
| 类型 | DTD ENTITY 声明格式 | DTD ELEMENT 声明格式 |
|---|---|---|
| 声明一个元素 | <!ENTITY 元素名称 类别> |
<!ELEMENT 元素名称 元素内容> |
| 空元素 | <!ENTITY 元素名称 EMPTY> |
<!ELEMENT 元素名称 EMPTY> |
| 只有 PCDATA 的元素 | <!ENTITY 元素名称 (#PCDATA)> |
<!ELEMENT 元素名称 (#PCDATA)> |
| 带有任何内容的元素 | <!ENTITY 元素名称 ANY> |
<!ELEMENT 元素名称 ANY> |
| 带有子元素(序列)的元素 | <!ENTITY 元素名称 (子元素名称1, 子元素名称2, …………)> |
<!ELEMENT 元素名称 (子元素名称1, 子元素名称2, …………)> |
DTD属性
属性声明语法:
1 | |
其中,元素名称即属性名称是我们自己编的,这里我们提一下属性类型及默认属性值。
属性类型的选项:
| 类型 | 描述 |
|---|---|
| CDATA | 值为字符串数据 (character data) |
| `(value1 | value2 |
| ID | 值为唯一的 id |
| IDREF | 值为另一个元素的 id |
| IDREFS | 值为其他 id 的列表 |
| NMTOKEN | 值为合法的 XML 名称 |
| NMTOKENS | 值为合法的 XML 名称的列表 |
| ENTITY | 值是一个实体 |
| ENTITIES | 值是一个实体列表 |
| NOTATION | 此值是符号的名称 |
| xml: | 值是一个预定义的 XML 值 |
默认属性值可使用下列值(也可以直接指定):
| 默认值 | 解释 |
|---|---|
| #REQUIRED | 属性值是必需的 |
| #IMPLIED | 属性值不是必需的 |
| #FIXED value | 属性值是固定的 |
示例,
1 | |
DTD实体
实体是用于定义引用普通文本或特殊字符的快捷方式的变量。
实体可在内部或外部进行声明。
实体引用是对实体的引用。
DTD实体的分类:
按实体有无参分类,实体分为一般实体和*参数实体;按实体使用方式分类,实体分为内部声明实体和引用外部实体*。
一般实体
声明:
1 | |
引用一般实体的方法:&实体名称;
ps:经实验,普通实体可以在DTD中引用,可以在XML中引用,可以在声明前引用,还可以在实体声明内部引用。
参数实体
声明:
1 | |
引用参数实体的方法:%实体名称;
ps:经实验,参数实体只能在DTD中引用,不能在声明前引用,也不能在实体声明内部引用。
(1)使用 % 实体名(这里面空格不能少) 在 DTD 中定义,并且只能在 DTD 中使用 %实体名; 引用
(2)只有在 DTD 文件中,参数实体的声明才能引用其他实体
(3)和通用实体一样,参数实体也可以外部引用
内部实体
声明:
1 | |
内部实体示例代码:
1 | |
外部实体
外部实体,用来引入外部资源。有SYSTEM和PUBLIC两个关键字,表示实体来自本地计算机还是公共计算机。
声明:
1 | |
外部实体示例代码:
1 | |
根据上面代码,我们可以发现,http://www.w3school.com.cn/dtd/entities.dtd 是一个 URL,属于公共计算机,更适合使用 PUBLIC 声明,但是我们还是用了SYSTEM,这也是可行的。
这里我们强调一下外部引用的两种方式:
SYSTEM:用于指向一个特定的 URI,通常是指向一个具体、私有的资源(如文件路径或特定 URL)。PUBLIC:用于引用一个公共标识符(public identifier),通常是为了引用标准化的或通用的外部 DTD 文件。
外部实体可支持http、file等协议。不同程序支持的协议不同:
| libxml2 | PHP | Java | .NET |
|---|---|---|---|
| file | file | http | file |
| http | http | https | http |
| ftp | ftp | ftp | https |
| php | file | ftp | |
| compress.zlib | jar | ||
| compress.bzip2 | netdoc | ||
| data | mailto | ||
| glob | gopher * | ||
| phar |
PHP支持的协议会更多一些,但需要一定的扩展:
| Scheme | Extension Required |
|---|---|
| https | openssl |
| ftps | openssl |
| zip | zip |
| ssh2.shell | ssh2 |
| ssh2.exec | ssh2 |
| ssh2.tunnel | ssh2 |
| ssh2.sftp | ssh2 |
| ssh2.scp | ssh2 |
| rar | rar |
| ogg | oggvorbis |
| expect | expect |

PHP引用外部实体常见的利用协议:
1 | |
注意:
1.其中从2012年9月开始,Oracle JDK版本中删除了对gopher方案的支持,后来又支持的版本是 Oracle JDK 1.7
update 7 和 Oracle JDK 1.6 update 35
2.libxml 是 PHP 的 xml 支持
XML相关安全问题
XML注入
XML注入简介
XML的设计宗旨是传输数据,而非显示数据。
XML注入是一种古老的技术,通过利用闭合标签改写XML文件实现的。
XML是一种数据组织存储的数据结构方式,安全的XML在用户输入生成新的数据时候应该只能允许用户接受的数据,需要过滤掉一些可以改变XML标签也就是说改变XML结构插入新功能(例如新的账户信息,等于添加了账户)的特殊输入,如果没有过滤,则可以导致XML注入攻击。
XML注入前提条件
(1)用户能够控制数据的输入
(2)程序将用户输入拼凑到xml中
注入实例
举个最简单的例子
1 | |
若攻击者刚好能掌控用户输入字段,输入
1 | |
最终修改结果为
1 | |
这样我们可以通过XML注入添加一个管理员账户
XML注入两大要素:标签闭合和获取XML表结构
XML注入防御
(1)对用户的输入进行过滤
(2)对用户的输入进行转义
| 预定义字符 | 转义后的预定义字符 |
|---|---|
< |
< |
> |
> |
& |
& |
' |
' |
" |
" |
XPath注入
什么是XPath?
我们讲XSL时提过XPath,它是XSL的三部分之一。这里我们详细讲一下它。
XPath 是一门在 XML 文档中查找信息的语言。XPATH可用来在XML文档中对元素和属性进行遍历。XPath 在 XML 文档中通过元素和属性进行导航,类似jquery选择器的选择路径。
XPATH 包含一个标准函数库:XPATH含有超过100个内建的函数。可以处理字符串值,数值,日期和时间比较,节点和QName处理,序列处理,逻辑值等等。
XPath的强大之处在于逻辑运算,使程序变得更有逻辑性,同时也会造成注入漏洞。
通过XPath注入攻击,可以攻击XML。XPath与SQL注入的方式类似。
XPath语法参考下面文章:
Xpath注入攻击原理
如果一个网站某应用程序将数据保存在XML中,并且对用户查询时的输入没有做限制。此时,攻击者提交了没有经过处理的输入,插入到 XPath 查询中,就产生了Xpath注入,这时候攻击者就可能通过控制查询,进行获取数据或者删除数据之类的操作。
可以这样理解,Xpath是xml路径语言,用于配置文件的查找。类似于SQL语言,数据库就是xml文件。因此只要是利用XPath语法的Web 应用程序如果未对输入的XPath查询做严格的处理都会存在XPath注入漏洞。比如一些登录地址页面,搜索页面需要与xml交互的位置。
所以,XPath注入攻击主要是通过构建特殊的输入(这些输入往往是XPath语法中的一些组合),这些输入将作为参数传入Web 应用程序,通过执行XPath查询而执行入侵者想要的操作。但注入对象不是数据库users表,而是一个存储数据的XML文件。因为xpath不存在访问控制,所以不会遇到许多在SQL注入中经常遇到的访问限制。 注入常出现的位置也就是cookie,headers,request parameters/input等。
注入实例
1、直接注入
假设有一张BookDB表,其中包括BookID、BookName、Price,用Sql Server查询图书ID时SQL语句代码如下:
1 | |
当我们输入1 or 1=1时,运行结果可以显示当前表中的所有数据。
XPath注入攻击与SQL注入原理相似,这时我们把BookDB换成XML,代码如下:
这里我们定义了6本书
1 | |
若需要查询编号为001的图书对应的书名,则XPath语句为:
1 | |
下面我们进行查询,部分代码如下
1 | |
结果为:
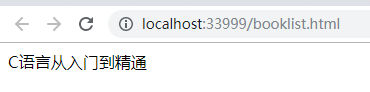
假设我们可以控制XPath语句,那么可以使用之前提到的or 1=1遍历全部的bookname,代码如下:
1 | |
运行结果为:
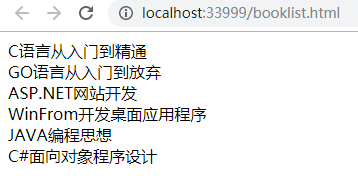
成功get所有的bookname。
XPath注入攻击利用两种技术,即XPath扫描和 XPath查询布尔化。
2、XPath盲注
1 | |
盲注手法:
先利用count(/*)判断根下节点,
1 | |
有返回结果证明存在一个根节点。
利用substring分割根节点的每个字符,猜解第一级节点:
1 | |
…
最终结果: root
然后盲注root的下一级节点,
判断root的下一级节点数:
1 | |
有返回结果证明存在一个root的下一级节点。
猜解root的下一级节点:
1 | |
最终结果:users
重复上述步骤,直至猜解出所有节点,最后来猜解节点中的数据或属性值。
Xpath注入攻击危害及防御
危害:
- 在URL及表单中提交恶意XPath代码,可获取到权限限制数据的访问权,并可修改这些数据。
- 可通过此类漏洞查询获取到系统内部完整的XML文档内容。
- 逻辑以及认证被绕过,它不像数据库那样有各种权限,xml没有各种权限的概念,正因为没有权限概念,因此利用xpath构造查询的时候整个数据库都会被用户读取。
防御:
- 数据提交到服务器上端,在服务端正式处理这批数据之前,对提交数据的合法性进行验证。
- 检查提交的数据是否包含特殊字符,对特殊字符进行编码转换或替换、删除敏感字符或字符串。
- 对于系统出现的错误信息,以IE错误编码信息替换,屏蔽系统本身的出错信息。
- 参数化XPath查询,将需要构建的XPath查询表达式,以变量的形式表示,变量不是可以执行的脚本。
- 通过MD5、SSL等加密算法,对于数据敏感信息和在数据传输过程中加密,即使某些非法用户通过非法手法获取数据包,看到的也是加密后的信息。 总结下就是:限制提交非法字符,对输入内容严格检查过滤,参数化XPath查询的变量。
XSLT注入
什么是XSLT?
XSLT 是XSL中最重要的部分,专门用于将XML文档转换为其他格式(如HTML、纯文本或其他XML格式)。实际就是给XML美化生成其他文档的东西。
XSLT常见用途是传输不同应用生成的文件数据和作为模版引擎。许多企业型应用程序广泛使用XSLT。比如,多租户开票应用程序可以允许客户端使用XSLT大量定制其发票。客户可以根据具体需要更改发票中显示的信息及其格式。
其他常见的应用:
- 报表功能
- 不同格式的数据导出
- 打印
- 邮件
XSLT语法可参考:https://www.runoob.com/xsl/xsl-tutorial.html
在描述这类攻击前,让我们通过一个实际例子来看看转换是如何进行的。
首先是下面这样的XML文件,包含了水果名和相关描述的列表:
1 | |
为了将XML文档转为纯文本,使用如下XSL转换:
1 | |
使用上述转换规则对数据进行转换的结果是下面的纯文本文件:
1 | |
XSLT注入的发现与利用
参考:https://xz.aliyun.com/news/24
下面我们重点讲一下XXE
XXE
XXE漏洞简介
XXE漏洞全称XML External Entity Injection 即XML外部实体注入。
XXE漏洞发生在应用程序解析XML输入时,没有禁止外部实体的加载,导致可加载恶意外部文件和代码,造成任意文件读取、命令执行、内网端口扫描、攻击内网网站、发起Dos攻击等危害。
XXE漏洞触发的点往往是可以上传xml文件的位置,没有对上传的xml文件进行过滤,导致可上传恶意xml文件。
解析xml在php库libxml,libxml>=2.9.0的版本中没有XXE漏洞。simplexml_load_string()可以读取XML
XXE利用
有回显
payload:
1 | |
Blind XXE
加载远程DTD
1 | |
先 %dtd 请求远程服务器(攻击机)上的 evil.xml,然后 %payload 调用了 %file ,%file 获取对方服务器上的敏感文件,最后替换 %send,数据被发送到我们远程的服务器,就实现了数据的外带
还有一种模板
1 | |
当然,我们也可以用DNSlog去判断有无XXE漏洞,但只能判断,感觉不能读文件(用处不大)
1 | |
加载本地DTD
如果目标有防火墙等设备,阻止了对外连接,可以采用基于错误回显的XXE。这种方式最流行的一种就是加载本地的DTD文件。
这个过程与先前引⽤远程 DTD 实现 Error-based XXE 的过程类似, 只不过将远程 DTD 转换成了本地 DTD
1 | |
/opt/IBM/Websphere/AppServer/properties/sip-app10.dtd是websphere上默认存在的dtd,可以通过加载它触发报错返回读取文件的内容。
在部分 Linux 系统上, 默认已经包含了⼀些 DTD ⽂件, 我们可以通过 Errorbased XXE 结合本地的这些 DTD ⽂件, 实现在不出⽹的情况下拿到回显
如下面两种payload:
1 | |
这段payload有点长,我们一点点来讲,这里burp直接介绍了一个内部的DTD:/usr/local/app/schema.dtd,这个内部DTD中有一个参数实体叫custom_entity,然后我们重写了这个参数实体,这里有个小知识点,在参数实体内部声明参数实体时关键字需要使用它的html编码格式,比如
1 | |
其他的和前面利用报错信息的XXE盲打方式是一样的。这种复用本地DTD的攻击方式重点在于我们能不能找到一个这样的本地DTD,现在很多应用程序都是开源的,所以我们可以下载源码包进行查找。
报错信息利用XXE泄露数据
有的时候我们可以通过触发XML解析错误将敏感信息泄漏在报错信息中,例如
1 | |
从上面我们能看到加载了一个不存在的文件触发XML报错,但是后面加载的file实体指定的文件是存在的,所以XML报错信息中就能泄漏这个文件的内容了
svg XXE
1 | |
除了 PHP 的 libxml 以外, Python 的⼀些第三⽅库也会存在 XXE 的问题, 例如 svglib
⾸先了解下 SVG, SVG 格式使⽤ XML 来存储⽮量图形, 那么⾃然 SVG 也会和 XML ⼀样⽀持外部实体这个功能, 也就有可能会存在 XXE
svglib 是⼀个处理 SVG ⽂件的 Python 第三⽅库, 它在 0.9.4 版本以前默认会解析 SVG 中的外部实体, 即存在 XXE
XInclude
payload:
1 | |
XXE打SSRF
SSRF的触发点通常是在ENTITY实体中,可以用来探测内网端口与攻击内网网站
paylaod:
1 | |
修改Content-Type
大部分的POST请求的Content-Type都是表单类型application/x-www-form-urlencoded,但是有的应用程序允许将其修改成text/xml,这样我们就可以将报文内容替换成XML格式的内容了,例如
1 | |
命令执行
在php环境下,xml命令执行需要php装有expect扩展,但该扩展默认没有安装,所以一般来说命令执行是比较难利用,但不排除。
1 | |
paylaod:
1 | |
Dos攻击
常见的XML炸弹:当XML解析器尝试解析该文件时,由于DTD的定义指数级展开,这个1K不到的文件会占用到3G的内存。
1 | |
原理:递归引用,lol 实体具体还有 “lol” 字符串,然后一个 lol2 实体引用了 10 次 lol 实体,一个 lol3 实体引用了 10 次 lol2 实体,此时一个 lol3 实体就含有 10^2 个 “lol” 了,以此类推,lol9 实体含有 10^8 个 “lol” 字符串,最后再引用lol9。
Java相关XXE
Java 中的 XXE 除了常规利⽤⽅式之外, 还有着其它的特点
例如可以通过 file:// 或 netdoc:// 协议列⽬录, 读取⽂件
除了利⽤ file 和 netdoc 协议列⽬录外, Java 中的 XXE 还可以利⽤ jar 协议上 传⽂件, 在某些情况下可以配合其它漏洞组合利⽤
jar:// 能够从远程获取 jar ⽂件, 然后将其中的内容进⾏解压并读取⽂件内容, 格 式如下
1 | |
在获取 jar 的过程中, Java 会将 jar/zip ⽂件作为临时⽂件保存在 /tmp ⽬录 (或其它路 径) 下, 然后获取压缩包内对应⽂件的内容, 最后将临时⽂件删除
绕过
伪协议
我们可以利用不同的协议
| 协议 | 使用方式 |
|---|---|
| file | file:///etc//passwd |
| php | php://filter/read=convert.base64-encode/resource=index.php |
| http | http://attacker.com/evil.dtd |
前面我们已经提到不同语言能使用的协议了,这里就不详解了
编码绕过
过滤如下
1 | |
但是⼤多数的 XML 解析器都⽀持多种编码, 例如 UTF-16 (UTF-16-BE, UTF-16-LE) 等, 并且存在不同的解析特点
以 libxml2 为例 (Python 的 lxml 库基于 libxml2), 它会在读取 XML 头的 encoding 字段之后⽴即更改编码, 然后再进⾏解析
我们可以通过 UTF-8 和 UTF-16BE 混合编码的⽅式, 让 libxml2 能够 正常解析 XML, 同时⼜不会触发 WAF 的规则
构造⽅式如下
1 | |
test.xml
1 | |
注意不能使⽤ burp, 因为 burp 会⾃动对编码进⾏转换
使⽤ python 脚本发送数据包
XXE漏洞防御
1、使用开发语言提供的禁用外部实体的方法
php:
1 | |
java:
1 | |
Python:
1 | |
2、过滤用户提交的XML数据
过滤关键字:<\!DOCTYPE和<\!ENTITY,或者SYSTEM和PUBLIC。
3、不允许XML中含有自己定义的DTD