PartA:密码技术 TaskA-1:对称加密算法的加密模式:ECBvs. CBC 文件pic_original.bmp 含有一张简单的位图图像。我们希望对该图像进行加密,使未持有密钥 的攻击者无法从密文中看出原图内容。请分别使用ECB(ElectronicCodebook)和CBC(CipherBlock Chaining)两种模式对该文件进行加密。
CBC模式:-aes-128-cbc
ECB模式:-aes-128-ecb
1 2 openssl enc -aes-128 -cbc -e -in pic_original.bmp -out p1.bmp -K 00112233445566778889 aabbccddeeff -iv 0102030405060708 openssl enc -aes-128 -ecb -e -in pic_original.bmp -out p2.bmp -K 00112233445566778889 aabbccddeeff
将加密后的文件当作图像文件进行显示。对于.bmp文件,前54字节为图像头部信息,必须保持 正确,查看器才能将文件识别为合法的.bmp图像。因此,我们用原始图像的头部替换加密图像的头部, 从而构造可被正常打开的“加密图像”。
你可以使用十六进制编辑器(如Bless)直接修改二进制文件。也可以使用下面的命令,从p1.bmp 中提取header,从p2.bmp中提取数据部分(从偏移55字节到文件末尾),再将二者拼接成一个新的.bmp 文件:
1 2 3 4 5 head -c 54 pic_original.bmp > header55 p1.bmp > body1 body1 > new1.bmp 55 p2.bmp > body2 body2 > new2.bmp
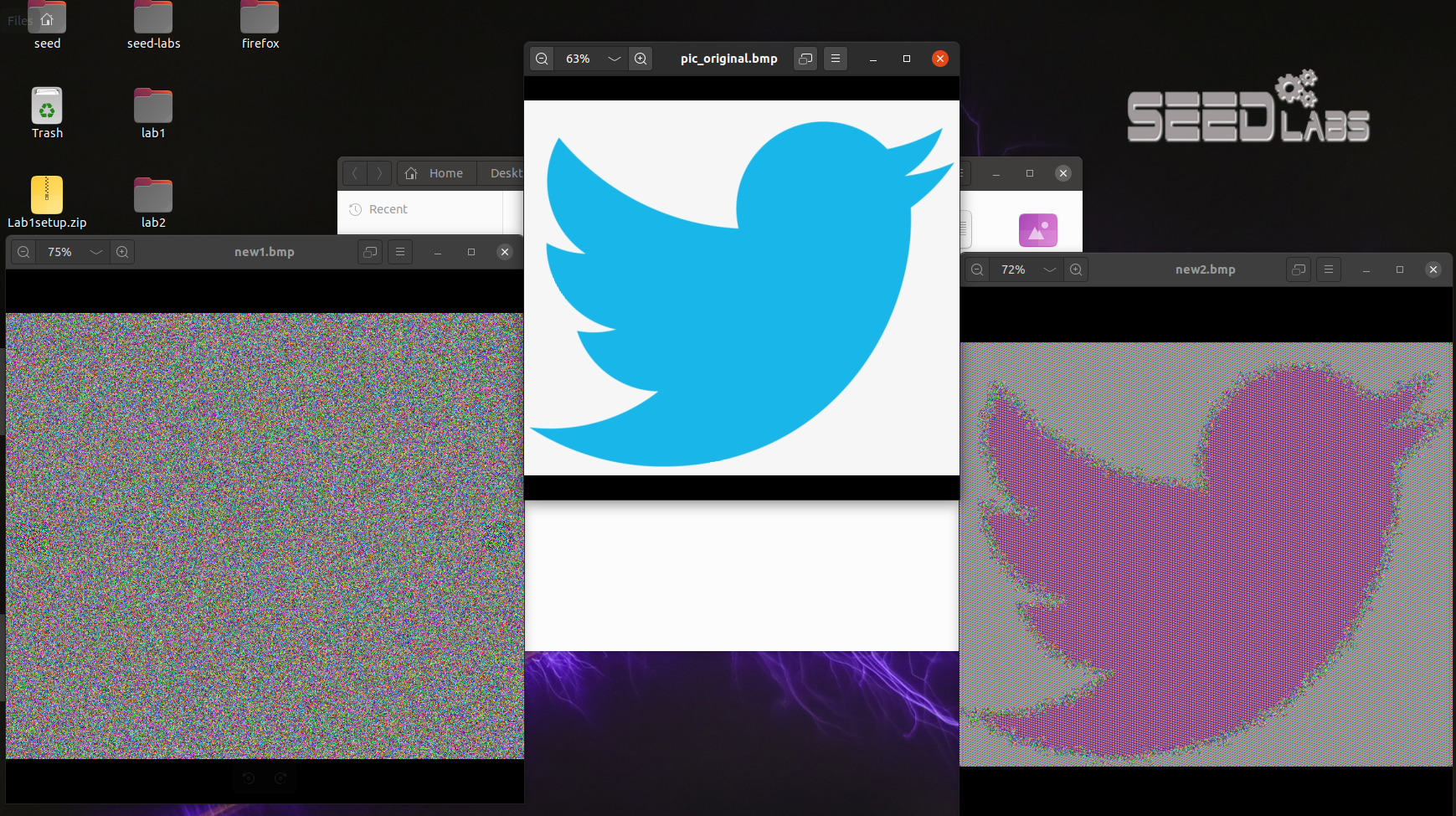
使用任意图像查看软件显示上述构造的“加密图像”。分别在ECB模式和CBC模式下,观察并比较 图像显示效果:在每种模式下,你是否仍能从加密图像中辨认出原始图像的轮廓或其他有用信息?请解释 你的观察结果,并在实验报告中附上截图。
左为CBC模式,中间为原始图像,右为ECB模式。
左边的图(CBC 模式)完全是一团杂乱的雪花,而右边的图(ECB 模式)还能看清轮廓,大致是一只小鸟
ECB (Electronic Codebook) 模式 是最简单的加密模式。把图片文件切成很多个固定大小的小块(比如 128 bit)。对每一个小块使用相同的密钥独立加密。
相同的明文块,在相同的密钥下,永远会生成相同的密文块。
在图片中的后果:原始图片中有大片的纯色区域(比如那只蓝色的小鸟)。这些区域由成千上万个完全相同的像素数据块组成。因为输入的数据块是相同的,ECB 加密后输出的密文块也是完全相同的。当你把这些密文重新拼回成图片时,原本是蓝色的区域现在变成了另一种颜色的“噪点”,但因为这一片区域的噪点纹理是一样的,原本的轮廓和形状就被完美地保留了下来。这就是为什么你依然能清晰地看到小鸟形状的原因。这种特性导致 ECB 模式容易受到 模式分析攻击 。
CBC (Cipher Block Chaining) 模式 引入了随机性和前后关联。初始化向量 (IV):加密第一个块时,先引入一个随机的 IV 进行异或运算。链接机制: 加密第二个块时,不仅取决于当前的明文,还取决于前一个密文块的结果。当前的明文块会先与前一个密文块进行异或(XOR),然后再进行加密。
这种“链接”效应意味着,前一个块的微小变化会雪崩式地影响后面所有的块。即使原始图片中有大片相同的蓝色区域,在加密过程中,因为每一个块的输入都混入了前一个块极其复杂的密文结果,所以输出的密文块也是完全不同的。
在图片中的后果:
数据的规律性被彻底打乱。输出的密文看起来不仅是随机的,而且没有任何可识别的图案或结构。因此,原本的图片变成了左边那样完全无法识别的“雪花点”或伪随机噪声。
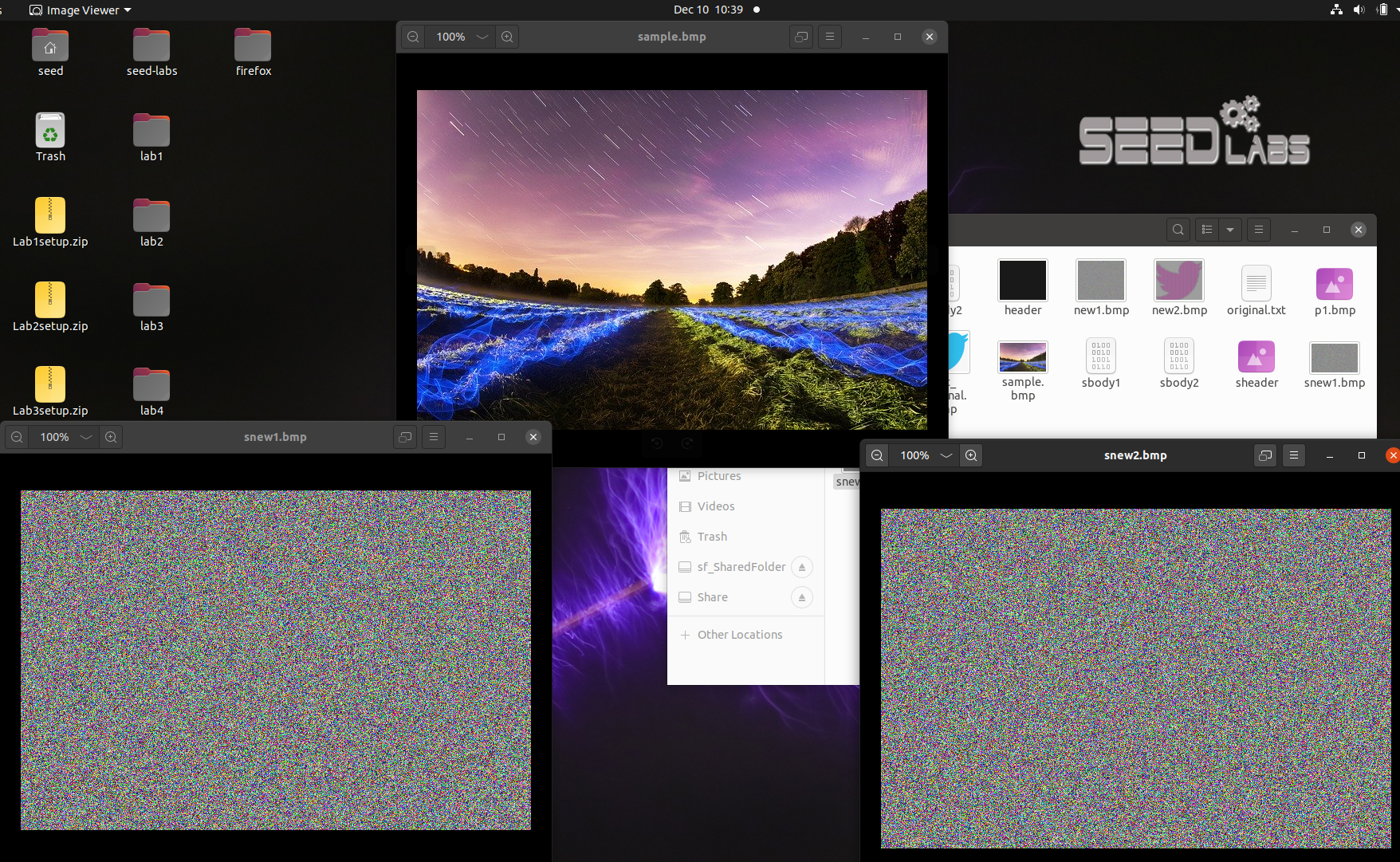
然后选择另一张图片(sample.bmp),重复上述实验步骤,对ECB和CBC模式下的显示效果进行对 比,并在实验报告中给出你的观察和分析(同样需附截图)。
1 2 openssl enc -aes-128-cbc -e -in sample .bmp -out sp1.bmp -K 00112233445566778889aabbccddeeff -iv 0102030405060708enc -aes-128-ecb -e -in sample .bmp -out sp2.bmp -K 00112233445566778889aabbccddeeff
1 2 3 4 5 head -c 54 sample.bmp > sheader 55 sp1.bmp > sbody1 sheader sbody1 > snew1.bmp 55 sp2.bmp > sbody2 sheader sbody2 > snew2.bmp
左为CBC模式,中间为原始图像,右为ECB模式。
这张图片使用CBC和ECB加密后都没有明显的特征了,原因是这张图片没有大面积的重复的色块,即使使用ECB模式加密也不会泄露图片的结构信息。
TaskA-2:哈希函数的单向性与抗碰撞性 密码学哈希函数通常需要满足单向性和抗碰撞性。在本实验中,我们将通过暴力穷举的方法来“攻击” 抗碰撞性,即尝试找到两个哈希值相同的不同文件。你的目标是:在给定一个文件的基础上,编写程序 找到另一个与之具有相同哈希值的文件。你可以使用任意编程语言(如C、Java、Shell等)实现该程序, 并可在程序中直接调用openssl命令来计算哈希值。
由于大多数标准哈希函数对暴力碰撞攻击具有极强的抵抗能力,直接使用完整的哈希输出进行穷举 在现实中往往需要极长时间。为了让实验在可接受时间内完成,我们人为缩短哈希值的有效长度为24 bit。具体地,在本任务中我们只使用SHA1哈希值的前24bit(即哈希输出的前6个十六进制字符),可 以理解为使用了一个“截断版”的单向散列函数。请设计一个程序,完成以下工作:
计算original.txt 的SHA1哈希值,并记录其前24bit(即前6个十六进制字符)。
1 2 openssl dgst -sha1 original.txt SHA1 (original.txt)
使用暴力穷举方法(例如生成随机字符串或系统性枚举候选内容),找到另一个与original.txt在 “截断后的SHA1值”(前24bit)上完全相同的文件。
在本任务中,你需要统计使用暴力穷举方法打破截断哈希抗碰撞性所需的尝试次数。请至少进行多 次实验,记录每次找到碰撞所需的尝试次数,并给出其平均值,结合理论期望进行简单分析。
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> #include <openssl/sha.h> #define TARGET_BITS 24 #define TARGET_BYTES 3 #define MAX_ATTEMPTS 100000000 #define MIN_LENGTH 5 #define MAX_LENGTH 20 #define PROGRESS_INTERVAL 100000 const char CHARSET[] = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()-_=+[]{}|;:,.<>?/~ \n\t" ;const int CHARSET_SIZE = sizeof (CHARSET) - 1 ;unsigned char target_hash[TARGET_BYTES];void generate_random_string (char *str, int length) for (int i = 0 ; i < length; i++) {rand () % CHARSET_SIZE];'\0' ;int check_collision (const char *data, int length) unsigned char hash[SHA_DIGEST_LENGTH];SHA1 ((unsigned char *)data, length, hash);return memcmp (hash, target_hash, TARGET_BYTES) == 0 ;int load_target_hash (const char *filename) fopen (filename, "rb" );if (!fp) {fprintf (stderr, "错误: 无法打开文件 %s\n" , filename);return 0 ;fseek (fp, 0 , SEEK_END);long file_size = ftell (fp);fseek (fp, 0 , SEEK_SET);unsigned char *content = malloc (file_size);if (!content) {fprintf (stderr, "错误: 内存分配失败\n" );fclose (fp);return 0 ;fread (content, 1 , file_size, fp);fclose (fp);unsigned char full_hash[SHA_DIGEST_LENGTH];SHA1 (content, file_size, full_hash);memcpy (target_hash, full_hash, TARGET_BYTES);printf ("\n原始文件: %s\n" , filename);printf ("文件大小: %ld 字节\n" , file_size);printf ("完整SHA1: " );for (int i = 0 ; i < SHA_DIGEST_LENGTH; i++) {printf ("%02x" , full_hash[i]);printf ("\n前24bit: " );for (int i = 0 ; i < TARGET_BYTES; i++) {printf ("%02x" , target_hash[i]);printf ("\n" );free (content);return 1 ;void save_collision (const char *data, int length, long long attempts) char filename[100 ];sprintf (filename, "collision_%lld.txt" , (long long )time (NULL ));fopen (filename, "w" );if (fp) {fwrite (data, 1 , length, fp);fclose (fp);printf ("碰撞文件已保存: %s\n" , filename);else {fprintf (stderr, "警告: 无法保存碰撞文件\n" );long long run_experiment (int experiment_num) printf ("\n========================================\n" );printf ("实验 %d\n" , experiment_num);printf ("========================================\n" );printf ("开始搜索碰撞...\n" );char candidate[MAX_LENGTH + 1 ];long long attempts = 0 ;time_t start_time = time (NULL );time_t last_progress = start_time;while (attempts < MAX_ATTEMPTS) {int length = MIN_LENGTH + (rand () % (MAX_LENGTH - MIN_LENGTH + 1 ));generate_random_string (candidate, length);if (check_collision (candidate, length)) {time_t end_time = time (NULL );double elapsed = difftime (end_time, start_time);printf ("\n✓ 找到碰撞!\n" );printf (" 尝试次数: %lld\n" , attempts);printf (" 耗时: %.0f 秒\n" , elapsed);printf (" 速度: %.0f 次/秒\n" , attempts / elapsed);printf (" 碰撞内容: \"" );for (int i = 0 ; i < length && i < 50 ; i++) {if (candidate[i] >= 32 && candidate[i] <= 126 ) {printf ("%c" , candidate[i]);else {printf ("\\x%02x" , (unsigned char )candidate[i]);printf ("\"\n" );unsigned char hash[SHA_DIGEST_LENGTH];SHA1 ((unsigned char *)candidate, length, hash);printf (" 验证哈希: " );for (int i = 0 ; i < TARGET_BYTES; i++) {printf ("%02x" , hash[i]);printf ("\n" );save_collision (candidate, length, attempts);return attempts;if (attempts % PROGRESS_INTERVAL == 0 ) {time_t current_time = time (NULL );if (difftime (current_time, last_progress) >= 5 ) { double elapsed = difftime (current_time, start_time);double speed = attempts / elapsed;printf (" 尝试: %lld (%.0f 次/秒)\n" , attempts, speed);printf ("\n✗ 未找到碰撞 (达到最大尝试次数)\n" );return -1 ;int main (int argc, char *argv[]) printf ("======================================================================\n" );printf ("哈希碰撞实验 - 高性能C语言版本\n" );printf ("攻击截断SHA1(前24bit)的抗碰撞性\n" );printf ("======================================================================\n" );srand (time (NULL ));const char *target_file = "original.txt" ;if (argc > 1 ) {1 ];if (!load_target_hash (target_file)) {return 1 ;printf ("\n理论分析:\n" );printf (" 哈希空间: 2^24 = 16,777,216\n" );printf (" 期望尝试次数: ~8,388,608\n" );int num_experiments = 5 ;printf ("\n开始进行 %d 次碰撞实验...\n" , num_experiments);long long results[num_experiments];int success_count = 0 ;long long total_attempts = 0 ;for (int i = 0 ; i < num_experiments; i++) {long long attempts = run_experiment (i + 1 );if (attempts > 0 ) {printf ("\n======================================================================\n" );printf ("实验结果统计\n" );printf ("======================================================================\n" );if (success_count > 0 ) {printf ("\n成功实验次数: %d/%d\n" , success_count, num_experiments);printf ("\n各次尝试次数:\n" );long long min_attempts = results[0 ];long long max_attempts = results[0 ];for (int i = 0 ; i < success_count; i++) {printf (" 实验 %d: %lld 次\n" , i + 1 , results[i]);if (results[i] < min_attempts) min_attempts = results[i];if (results[i] > max_attempts) max_attempts = results[i];double avg_attempts = (double )total_attempts / success_count;printf ("\n统计数据:\n" );printf (" 平均尝试次数: %.2f\n" , avg_attempts);printf (" 最少尝试次数: %lld\n" , min_attempts);printf (" 最多尝试次数: %lld\n" , max_attempts);long long theoretical = 8388608 ;double deviation = ((avg_attempts - theoretical) / theoretical) * 100 ;printf ("\n理论对比:\n" );printf (" 理论期望: %lld\n" , theoretical);printf (" 实际平均: %.2f\n" , avg_attempts);printf (" 偏差: %.2f%%\n" , deviation);else {printf ("\n所有实验均未找到碰撞\n" );printf ("\n======================================================================\n" );printf ("实验完成!\n" );printf ("======================================================================\n" );return 0 ;
sh脚本运行结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 ./run.sh ====================================================================== 哈希碰撞实验 - 自动化脚本 ====================================================================== 步骤 1/5: 检查环境... ---------------------------------------------------------------------- 步骤 2/5: 分析目标文件... ---------------------------------------------------------------------- 步骤 3/5: 编译程序... ---------------------------------------------------------------------- 步骤 4/5: 运行实验... ---------------------------------------------------------------------- 哈希空间: 2^24 = 16,777,216 期望尝试次数: ~8,388,608 尝试次数: 21057531 耗时: 2 秒 速度: 10528766 次/秒 碰撞内容: "Q$t48.};YR#+E,Z" 验证哈希: a2bd2a 尝试次数: 1092213 耗时: 0 秒 速度: inf 次/秒 碰撞内容: "dPhTbJ" 验证哈希: a2bd2a 尝试次数: 10672179 耗时: 1 秒 速度: 10672179 次/秒 碰撞内容: "]pb.bMJ" 验证哈希: a2bd2a 尝试: 36500000 (7300000 次/秒) 尝试次数: 52969328 耗时: 6 秒 速度: 8828221 次/秒 碰撞内容: "*l}Hg5(s*Q" 验证哈希: a2bd2a 尝试次数: 8088253 耗时: 0 秒 速度: inf 次/秒 碰撞内容: "P_hikI(q" 验证哈希: a2bd2a 实验 1: 21057531 次 实验 2: 1092213 次 实验 3: 10672179 次 实验 4: 52969328 次 实验 5: 8088253 次 平均尝试次数: 18775900.80 最少尝试次数: 1092213 最多尝试次数: 52969328 理论期望: 8388608 实际平均: 18775900.80 偏差: 123.83% 步骤 5/5: 验证结果... ---------------------------------------------------------------------- 完整SHA1: a2bd2a86bf93e650708e6fc4b4af13140f596075 前24bit: a2bd2a ✓ 验证成功! 内容预览: dPhTbJ 完整SHA1: a2bd2a43b0d133ad81134972630e33670acf6c96 前24bit: a2bd2a ✓ 验证成功! 内容预览: ]pb.bMJ _1765385025.txt 完整SHA1: a2bd2a26062b57ae271bd7679f94433d1051b708 前24bit: a2bd2a ✓ 验证成功! 内容预览: P_ hikI(q_*.txt 2. 手动验证: openssl dgst -sha1 collision_ *.txt3. 撰写实验报告 ======================================================================
碰撞文件 1: collision_1765385017.txt
碰撞文件 2: collision_1765385018.txt
碰撞文件 3: collision_1765385025.txt
各次尝试次数:
统计数据:
理论对比:
PartB:随机数的安全应用 生成随机数是安全软件中非常常见的任务。在许多情况下,加密密钥不是由用户提供的,而是在软件 内部生成的。它们的随机性非常重要。否则,攻击者可以预测加密密钥,从而达到破坏加密目的。许多开 发人员从其先前的经验中知道如何生成随机数(例如用于蒙特卡洛模拟),因此他们使用类似的方法生成 用于安全目的的随机数。不幸的是,随机数序列对于蒙特卡洛模拟可能是好的,但对于加密密钥则可能是 不好的。开发人员需要知道如何生成安全的随机数,否则就会犯错。在一些著名的产品(包括Netscape 和Kerberos )中也犯过类似的错误
TaskB-1:用错误的方式生成加密密钥 要生成高质量的伪随机数序列,必须从足够随机且不可预测的熵源出发;否则,生成结果将具有较强 的可预测性,从而不适合作为加密密钥。下面的程序使用当前时间作为伪随机数生成器的种子来生成密 钥:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <stdio.h> #include <stdlib.h> #include <time.h> #define KEYSIZE 16 void main () int i;char key[KEYSIZE];printf ("%lld\n" , (long long ) time(NULL ));NULL )); for (i = 0 ; i< KEYSIZE; i++){256 ;printf ("%.2x" , (unsigned char )key[i]);printf ("\n" );
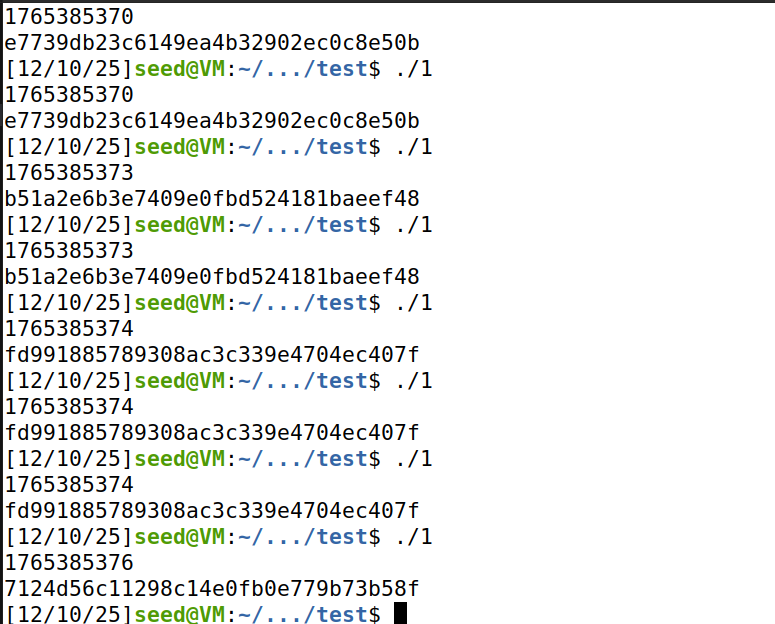
库函数time()以自Unix纪元1970-01-01 00:00:00 +0000 (UTC)起所经过的秒数形式返回当前时 间。请首先在未修改代码的情况下多次运行上述程序,记录(截图)并描述输出结果。
第一行输出的是从纪元 1970-01-01 00:00:00 +0000 (UTC) 到现在的秒数,第二行输出的是以当前时间作为随机数种子产生的加密密钥。
可以发现,当初始化随机数生成器的随机数种子不一样时,产生的加密密钥也不同。但是如果我们一秒内执行了两次该程序,它们就会使用相同的随机数种子生成随机数,生成的随机数是相同的。
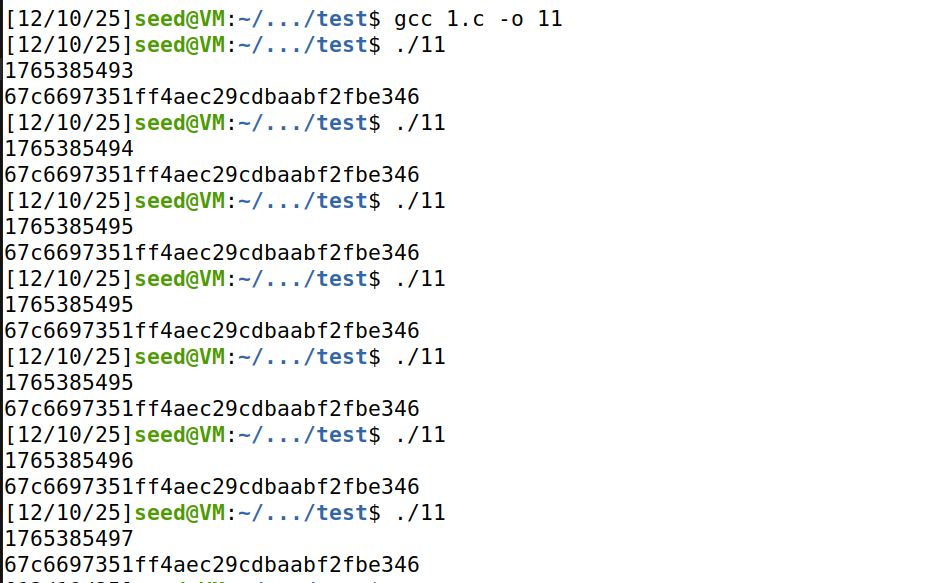
随后,将第行(即对srand(time(NULL))的调用)注释掉,重新编译并多次运行该程序,记录(截 图)并描述此时输出的变化。
可以发现,每次运行程序,即使时间戳不同,生成的随机数都是相同的,这是因为我们注释掉了 srand(time(NULL));,rand() 函数会默认将 1 设置为随机数种子,所以导致每次运行生成的加密密钥都是相同的。
time(NULL):用于获取当前时间;srand():用于设置 rand() 函数的种子。
TaskB-2:利用弱密钥生成方案恢复加密密钥 2019 年11月3日,Alice完成了纳税申报表,并将报税表保存为PDF文件存储在本地磁盘上。为保 护该文件,她使用TaskB-1中描述的密钥生成程序产生对称密钥,并用该密钥对PDF文件进行了加密。 她将密钥手写记录在笔记本上,并锁在保险箱中妥善保管。
几个月后,Bob非法入侵了Alice的计算机,并获得了该加密纳税申报表的副本。由于Alice是一家 大型公司的首席执行官,该文件具有很高的敏感性和经济价值。
Bob 无法直接获得加密密钥,但他在Alice的计算机上看到了密钥生成程序,并怀疑Alice的密钥是 由该程序生成的。他还注意到,加密文件的时间戳为2019-11-03 20:15:27,于是推测密钥很可能是在 该时间戳之前的两小时内生成的。
由于目标文件是PDF文件,因此其文件头具有高度可预测性。PDF文件的文件头以版本号开始,在 本实验场景中,当时最常见的版本是PDF-1.5,即文件头的前8个字节固定为%PDF-1.5。紧随其后的8个 字节的数据也较为容易预测。因此,Bob实际上掌握了前16个字节的明文。根据加密文件的元数据,他 还知道该文件是使用aes-128-cbc进行加密的。由于AES的分组大小为128bit(即16字节),一个明文 分组恰好由16字节组成,也就是说Bob知道一个完整的明文分组及其对应的密文分组。
此外,Bob还能从加密文件中获得初始向量(IV,IV本身并未被加密)。综上,Bob已知的信息如下:
1 2 3 4 Plaintext: 255044462 d312e350a25d0d4c5d80a34Ciphertext: 2 f6f084df77f07de8941232258de6704IV: 1 a2b3c4d5e6f70717273747576777879
你的任务是帮助Bob找出Alice的加密密钥,从而解密整个文档。你需要编写一个程序,在推测的时 间范围内枚举所有可能的密钥,并利用已知的明文–密文分组进行验证。如果密钥是由真正不可预测的随 机数生成器产生的,那么该任务在计算上将无法完成;但是,由于Alice在密钥生成程序中使用了time() 作为伪随机数生成器的种子,极大地缩小了密钥空间,因此你应当能够在合理时间内恢复她的密钥。
在实现过程中,你需要根据候选时间戳,仿照Task1中的密钥生成逻辑重新生成密钥。你可以使用 date 命令打印出指定时间距离Unix纪元1970-01-01 00:00:00 +0000 (UTC)的秒数。例如:
1 2 $ date-d "2019-11-03 19:00:00" +1572807600
创建一个名为 crack_key.c 的文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> #include <openssl/evp.h> #define KEYSIZE 16 void hex_to_bytes (const char * hex, unsigned char * bytes) for (int i = 0 ; i < 16 ; i++) {sscanf (hex + 2 *i, "%2hhx" , &bytes[i]);void print_bytes (const char * label, unsigned char * bytes, int len) printf ("%s: " , label);for (int i=0 ; i<len; i++) printf ("%.2x" , bytes[i]);printf ("\n" );int main () const char *plaintext_hex = "255044462d312e350a25d0d4c5d80a34" ;const char *ciphertext_hex = "2f6f084df77f07de8941232258de6704" ;const char *iv_hex = "1a2b3c4d5e6f70717273747576777879" ;unsigned char plaintext[16 ];unsigned char ciphertext[16 ];unsigned char iv[16 ];unsigned char calculated_ciphertext[32 ]; int outlen, tmplen;hex_to_bytes (plaintext_hex, plaintext);hex_to_bytes (ciphertext_hex, ciphertext);hex_to_bytes (iv_hex, iv);long long start_time = 1572776127 ; long long end_time = 1572783327 ; unsigned char key[KEYSIZE];printf ("Brute-forcing key from timestamp %lld to %lld...\n" , start_time, end_time);for (long long t = start_time; t <= end_time; t++) {srand ((unsigned int )t);for (int i = 0 ; i < KEYSIZE; i++) {rand () % 256 ;EVP_CIPHER_CTX_new ();EVP_EncryptInit_ex (ctx, EVP_aes_128_cbc (), NULL , key, iv);EVP_CIPHER_CTX_set_padding (ctx, 0 ); if (!EVP_EncryptUpdate (ctx, calculated_ciphertext, &outlen, plaintext, 16 )) {EVP_CIPHER_CTX_free (ctx);continue ;EVP_EncryptFinal_ex (ctx, calculated_ciphertext + outlen, &tmplen);EVP_CIPHER_CTX_free (ctx);if (memcmp (calculated_ciphertext, ciphertext, 16 ) == 0 ) {printf ("\n[SUCCESS] Key Found!\n" );printf ("Timestamp (Seed): %lld\n" , t);print_bytes ("Key" , key, 16 );return 0 ;printf ("\n[FAILURE] Key not found within the specified time range.\n" );return 1 ;
在 Linux 终端中执行以下命令(需要链接 crypto 库):
1 2 gcc crack_key.c -o crack_key -lcrypto ./crack_ key
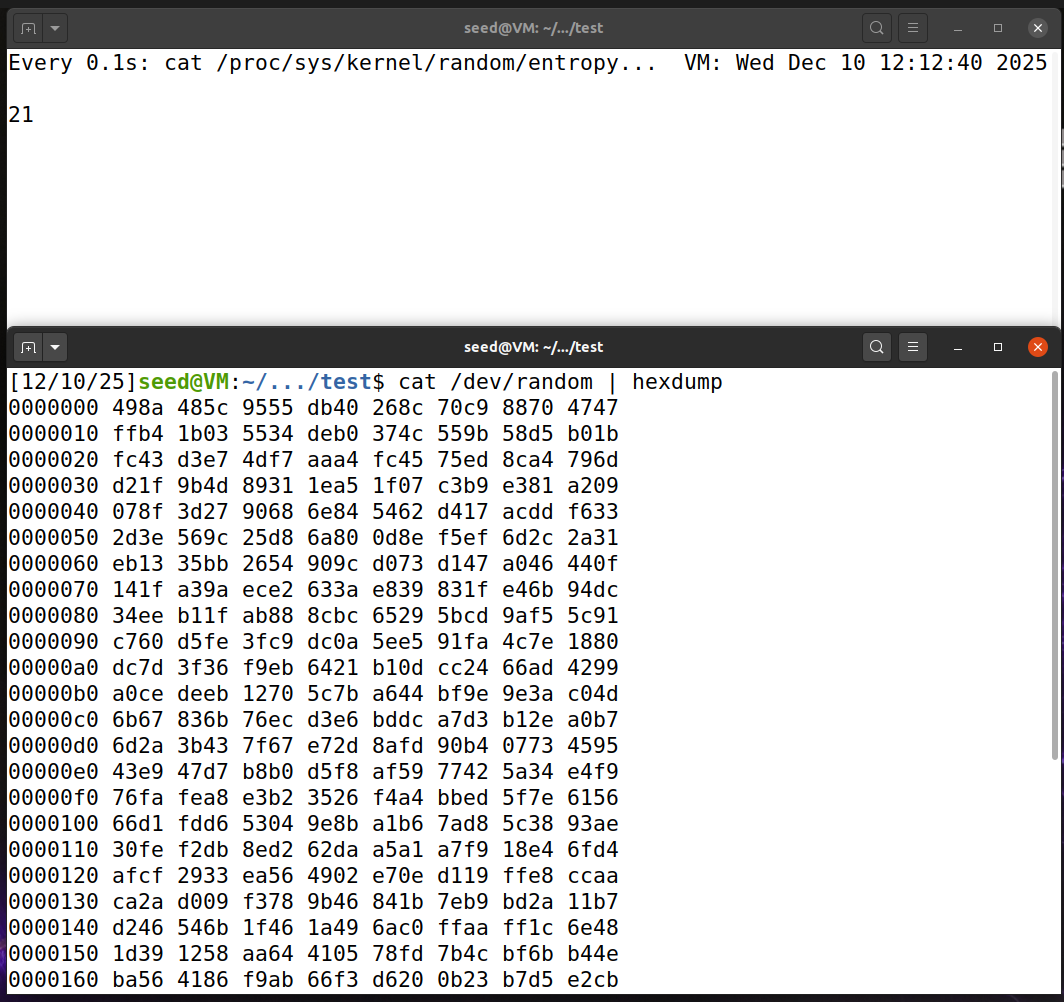
TaskB-3:从/dev/random中获取随机数 Linux 将从物理资源收集的随机数据存储到一个随机池中,然后使用两个设备将随机源转换为伪随机 数。这两个设备是/dev/random和/dev/urandom。它们有不同的行为。/dev/random设备是阻塞设备。 即,每当该设备给出随机数时,随机池的熵将减小。当熵达到零时,/dev/random将阻塞,直到获得足够 的随机性为止。
让我们设计一个实验来观察/dev/random设备的行为。我们将使用cat命令持续从/dev/random中 读取伪随机数。我们将输出通过管道传递到hexdump以便获得良好的输出。
1 cat /dev/random | hexdump
当不移动鼠标也不键入任何内容时,发现不会有新的伪随机数生成,只有当移动鼠标时,才会有新的伪随机数生成。
问题:假设一个服务器使用/dev/random与客户端生成随机会话密钥。请描述你将如何对这样的一个服 务器发起拒绝服务(DoS)攻击。
熵耗尽攻击(Entropy Starvation Attack): 如果服务器在建立连接(如 SSL/TLS 握手)或生成会话密钥(Session Key)时强制使用 /dev/random,由于 /dev/random 在熵不足时会阻塞进程,攻击者可以利用这一特性耗尽服务器的熵池。
攻击步骤:
发起大量连接请求: 攻击者编写脚本,向目标服务器发起大量并发的连接请求(例如,发起大量的 HTTPS 连接握手,或者 SSH 连接请求)。触发密钥生成: 每一次新的连接握手,服务器都需要生成一个新的随机数作为会话密钥或用于密钥交换协议(如 Diffie-Hellman)。服务器尝试从 /dev/random 读取数据。耗尽熵池: 由于攻击者的请求频率极高,服务器消耗随机数的速度远远超过了其通过物理事件(服务器通常没有鼠标键盘操作,熵来源本就较少,主要靠网络中断和磁盘读写)收集熵的速度。造成拒绝服务:
服务器的熵池迅速降为 0。
服务器端负责处理连接的进程在读取 /dev/random 时被挂起(阻塞),进入等待状态。
服务器无法完成当前的握手,也无法处理新的合法用户的连接请求,表现为服务器无响应或响应极慢,从而实现了拒绝服务(DoS)。
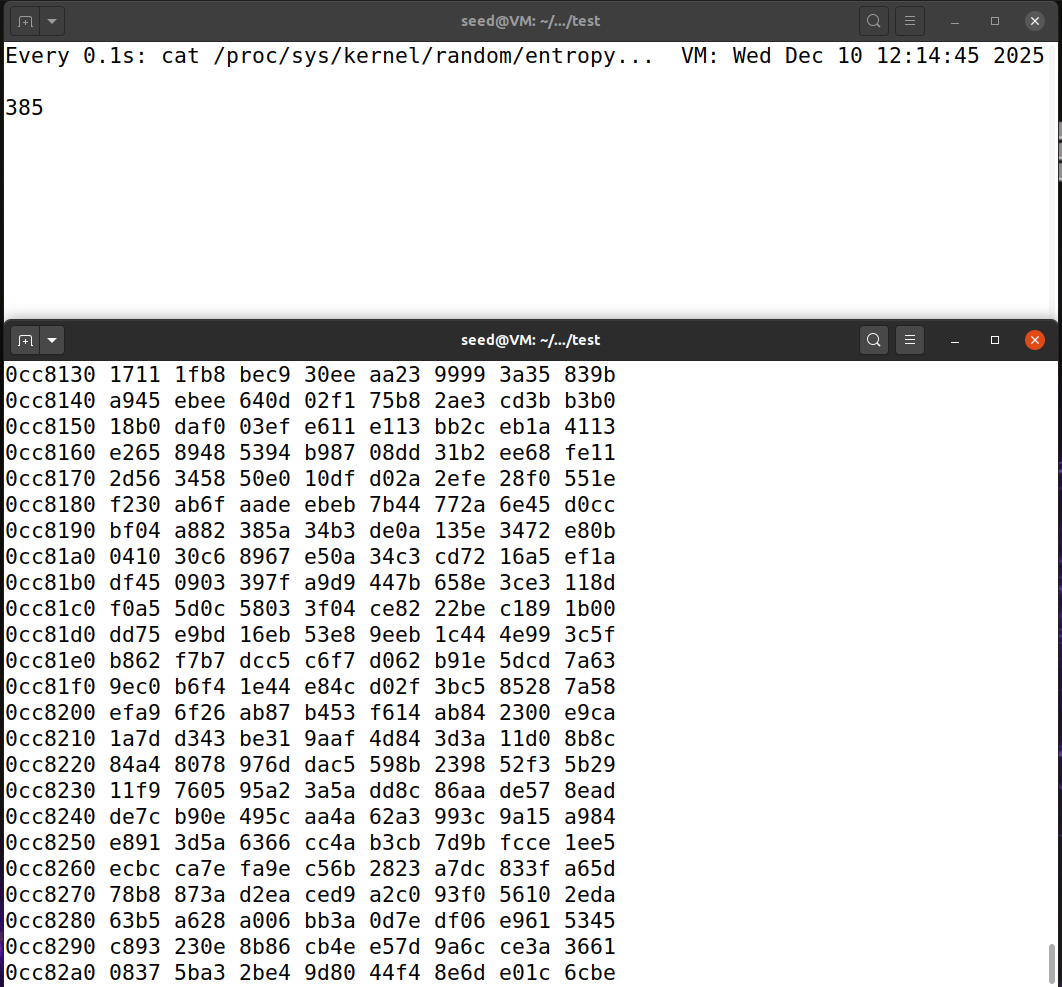
TaskB-4:从 /dev/urandom获取伪随机数 Linux提供了另一种方式,可以通过 /dev/urandom设备访问随机池。/dev/random和 /dev/urandom 都可以使用随机池中的数据生成伪随机数。当熵不足时,/dev/random将会暂停,而 /dev/urandom会继 续生成新的数。将随机池中的数据视作“种子”,我们可以使用种子想生成多少随机数就生成多少。
让我们来看看/dev/urandom的行为。我们再次使用cat从设备中获取伪随机数。请运行下面的命令, 描述移动鼠标是否会影响结果。
1 cat /dev/urandom | hexdump
/dev/urandom 会源源不断地输出伪随机数,即使不移动鼠标也会生成,移动鼠标时,也会一直生成,并且内核熵在一直增加。
让我们测量随机数的质量。我们可以使用一个名为ent的工具,该工具已经安装在我们的虚拟机中。 根据其手册所言:“ent对存储在文件中的字节序列进行各种测试,并报告这些测试的结果。该程序对于评 估加密和统计采样应用程序,压缩算法以及其他文件信息密度受关注的应用程序的伪随机数生成器很有 用”。让我们首先从/dev/urandom生成1MB的伪随机数,并将其保存在文件中。然后,在该文件上运行 ent。请描述你的结果,并分析随机数的质量是否良好。
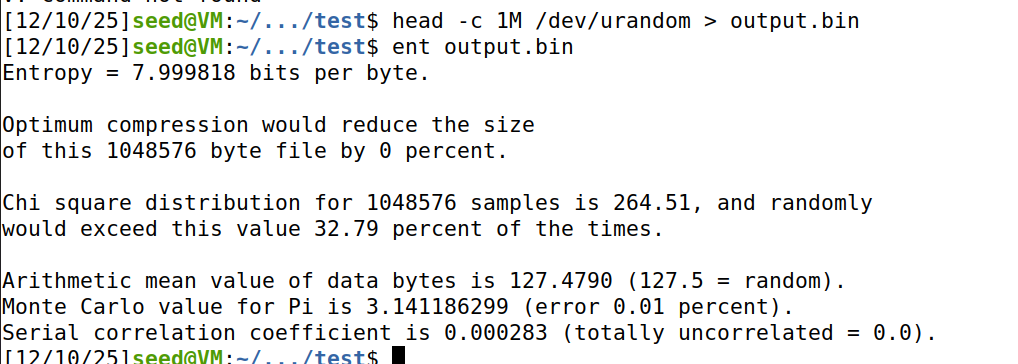
1 2 head -c 1M /dev/urandom > output.bin
结果表明:/dev/urandom 生成的随机数质量极高,非常接近真正的随机噪声。
熵值 (Entropy)
1 Entropy = 7.999818 bits per byte.
结果是 7.999818,极其接近理论最大值 8.0。
这意味着数据被压缩的可能性几乎为零,数据中几乎没有冗余信息,随机性极好。
压缩率 (Optimum compression)
1 Optimum compression would reduce the size of this 1048576 byte file by 0 percent.
结果是 0 percent。
随机数据是不可压缩的。如果能被压缩,说明数据中有重复模式。0% 的压缩率进一步印证了上面的高熵值。
卡方分布 (Chi square distribution)
1 Chi square distribution for 1048576 samples is 264 .51 , and randomly would exceed this value 32 .79 percent of the times.
对于完美的随机序列,这个百分比应该在 10% 到 90% 之间。如果小于 1% 或大于 99%,则说明序列“可疑”(要么太不随机,要么“太过于完美以至于不像随机”)。
结果是 32.79%。
这个数值完全落在正常范围内,说明数据的分布非常均匀,没有明显的偏差。
算术平均值 (Arithmetic mean value)
1 Arithmetic mean value of data bytes is 127 .4790 (127 .5 = random).
结果 127.4790 非常接近 127.5。
说明 0 和 255 之间的数值出现得非常平衡,没有偏向大数或小数。
蒙特卡洛法求 Pi 值 (Monte Carlo value for Pi)
1 Monte Carlo value for Pi is 3 .141186299 (error 0 .01 percent).
结果 3.1411... 与真实的 Pi (3.14159...) 误差仅为 0.01%。
误差极小,说明数据在二维坐标上的分布非常均匀。
序列相关系数 (Serial correlation coefficient)
1 Serial correlation coefficient is 0 .000283 (totally uncorrelated = 0 .0 ).
结果 0.000283 极其接近 0。
说明当前的字节和下一个字节之间几乎没有任何关联,无法通过前一个数预测后一个数。
理论上讲,/dev/random设备更加安全,但是实践上并没有很大的差异,因为/dev/urandom使用的 “种子”是随机的和不可预测的(当有新的随机数据输入时/dev/urandom会重新设置种子)。一个比较大的 问题是/dev/random的阻塞行为可能导致拒绝服务攻击。因此,比较推荐使用/dev/urandom来获取随机 数。要在我们的程序中这样做,只需要直接从这个设备文件中读取。下面的代码片段展示了如何实现。
1 2 3 4 5 6 #define LEN 16 unsigned char *key = (unsigned char *) malloc (sizeof (unsigned char )*LEN);fopen ("/dev/urandom" , "r" );fread (key, sizeof (unsigned char )*LEN, 1 , random);fclose (random);
请修改上面的代码片段来生成一个512bit的加密密钥。请编译并运行你的代码,输出这些数并将屏 幕截图放在报告里。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <stdlib.h> #define LEN 64 int main () {unsigned char *key = (unsigned char *) malloc (sizeof (unsigned char ) * LEN);"/dev/urandom" , "r" );size_t bytes_read = fread(key, sizeof (unsigned char ), LEN, random);printf ("Generated 512-bit key:\n" );for (size_t i = 0 ; i < LEN; i++) {printf ("%02x" , key[i]);printf ("\n" );free (key);return 0 ;